Florence-2, model visió de Microsoft
Florence-2 és un model de visió-llenguatge de codi obert desenvolupat per Microsoft i llançat sota la llicència MIT. Tot i la seva mida reduïda, demostra fortes capacitats de zero-shot i ajust fi en tasques com la descripció d’imatges, detecció d’objectes, assignació de significats i segmentació. Aquest model destaca pel seu rendiment comparable a models molt més grans, com Kosmos-2, gràcies a l’ús del gran conjunt de dades FLD-5B, que inclou 126 milions d’imatges i 5,4 mil milions d’anotacions visuals.
Florence-2 aborda la diversitat de tasques de visió unificant la representació i entrenant un sol model capaç d’executar més de deu tasques, en lloc d’una sèrie de models separats. Aquest enfocament requereix un nou conjunt de dades, de manera que es va crear el FLD-5B automatitzant el procés amb models especialitzats existents. FLD-5B, tot i que encara no està disponible públicament, inclou caixes, màscares i diferents nivells de descripcions, utilitzant imatges d’altres conjunts de dades de visió per ordinador.
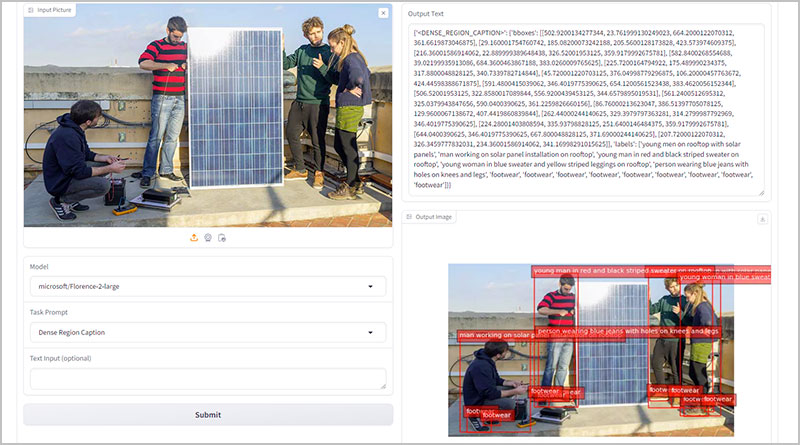
L’arquitectura del model pren imatges i prompts de tasques com a entrada, generant els resultats desitjats en format de text. Utilitza un codificador de visió DaViT per convertir imatges en incrustacions de tokens visuals, que es concatenen amb incrustacions de text generades per BERT i es processen mitjançant un codificador-decodificador multimodal basat en transformers. Per a tasques específiques de regions, s’afegeixen tokens de ubicació representant coordenades quantificades al vocabulari del tokenitzador.
Florence-2 és més petit i precís que els seus predecessors, amb dues versions: Florence-2-base i Florence-2-large, amb 0.23 mil milions i 0.77 mil milions de paràmetres respectivament. Això permet la seva implementació fins i tot en dispositius mòbils. Tot i la seva mida, Florence-2 obté millors resultats de zero-shot que Kosmos-2 en tots els benchmarks, tot i que Kosmos-2 té 1.6 mil milions de paràmetres.
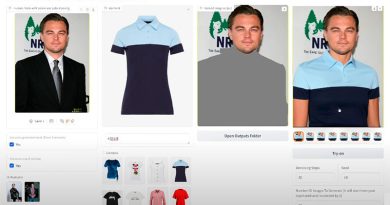
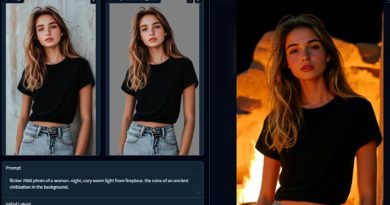
El model ofereix resultats destacats en tasques com assignació de significats visual, OCR amb regió i detecció d’objectes de vocabulari obert. Florence-2 representa un avenç significatiu en els models de visió-llenguatge al combinar una arquitectura lleugera amb capacitats robustes, fent que sigui altament accessible i versàtil per a aplicacions del món real, especialment en dispositius amb recursos limitats.