DeepSeek-R1: raonador open source
DeepSeek, la startup xinesa d’intel·ligència artificial, ha llançat DeepSeek-R1, un model de raonament avançat que competeix amb gegants com OpenAI o1. Basat en el innovador DeepSeek V3, no només iguala en rendiment en matemàtiques, programació i raonament lògic, sinó que ho fa a un cost dràsticament inferior, amb estalvis del 90-95% enfront dels seus rivals comercials.
Característiques destacades de DeepSeek-R1
DeepSeek-R1 utilitza una combinació d’aprenentatge per reforç (RL) i entrenament supervisat per resoldre problemes complexos mitjançant cadenes de raonament avançades. En proves de referència va obtenir:
- 79,8% a l’AIME 2024 (raonament matemàtic avançat).
- 97,3% al MATH-500 (resolució de problemes matemàtics).
- Una puntuació de 2.029 a Codeforces, superant el 96,3% dels programadors humans.
Aquests assoliments el posicionen com un model competitiu, fins i tot enfront de models més grans com GPT-4o i Claude 3.5.
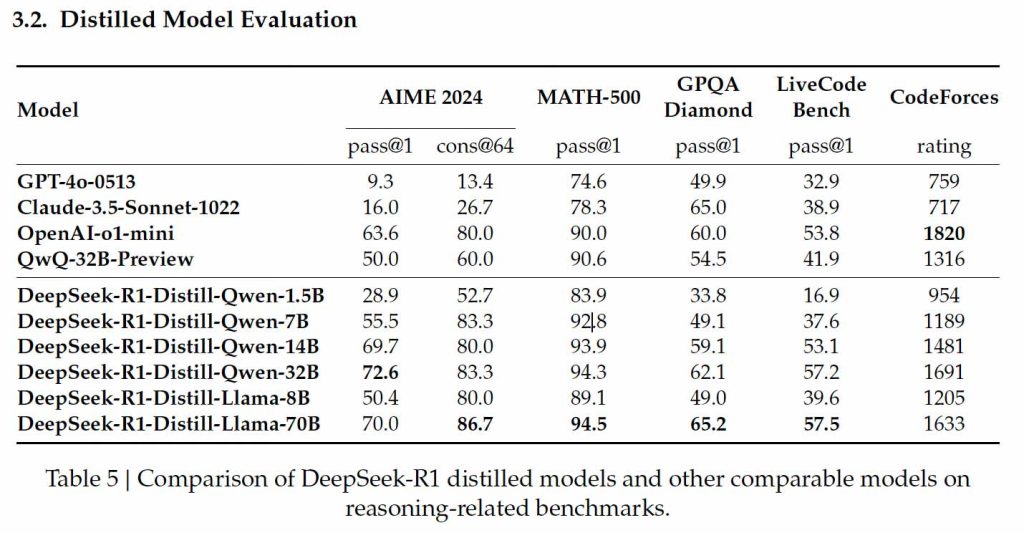
Models destil·lats de DeepSeek-R1
La destil·lació permet crear versions més petites i eficients de models grans, mantenint capacitats clau de raonament mentre es redueixen els requisits computacionals. DeepSeek va aplicar aquesta tècnica a les seves arquitectures Qwen i Llama, generant models compactes ideals per a la seva instal·lació en maquinari domèstic.
Models destil·lats basats en Qwen
- DeepSeek-R1-Qwen-1.5B: Compacte, amb un 83,9% al MATH-500, ideal per a matemàtiques bàsiques. No obstant això, el seu rendiment és limitat en programació (16,9% a LiveCodeBench).
- DeepSeek-R1-Qwen-7B: Aconsegueix un 92,8% al MATH-500 i un 49,1% al GPQA Diamond, però segueix sent moderat en tasques de codificació (37,6% a LiveCodeBench).
- DeepSeek-R1-Qwen-14B: Destaca al MATH-500 (93,9%) i al GPQA Diamond (59,1%), amb un millor rendiment en programació (53,1% a LiveCodeBench i 1.481 a Codeforces).
- DeepSeek-R1-Qwen-32B: El model més avançat basat en Qwen, amb un 94,3% al MATH-500 i 62,1% al GPQA Diamond, juntament amb un rendiment versàtil en programació (57,2% a LiveCodeBench i 1.691 a Codeforces).
Models destil·lats basats en Llama
- DeepSeek-R1-Llama-8B: Compacte i accessible, obté un 89,1% al MATH-500 i un rendiment raonable al GPQA Diamond (49,0%). En codificació, les seves capacitats són limitades (39,6% a LiveCodeBench).
- DeepSeek-R1-Llama-70B: El més gran i potent, amb un 94,5% al MATH-500 i un 86,7% a l’AIME 2024. El seu rendiment a LiveCodeBench (57,5%) i Codeforces (1.633) el posiciona com una alternativa eficient fins i tot enfront de l’o1-mini d’OpenAI.
Accessibilitat i cost
DeepSeek-R1 i els seus models destil·lats estan disponibles a Hugging Face amb una llicència MIT, preparats per a instal·lació local. Això democratitza l’accés a tecnologia avançada, permetent que desenvolupadors amb maquinari domèstic utilitzin models com Llama-8B i Qwen-7B. A més, els costos són significativament menors:
- 0,55 $ per milió de tokens d’entrada.
- 2,19 $ per milió de tokens de sortida, enfront dels 15 $ i 60 $ d’OpenAI o1.
Preguntes freqüents
Què és DeepSeek-R1?
És un model de raonament de codi obert que iguala el rendiment d’OpenAI o1, però amb un cost significativament menor.
Què són els models destil·lats de DeepSeek?
Són versions compactes i eficients de DeepSeek-R1, dissenyades per executar-se en maquinari domèstic sense comprometre capacitats essencials.
On estan disponibles els models de DeepSeek?
Es troben a Hugging Face amb llicència MIT per a descàrrega i ús en projectes personals o comercials.
Quins són els avantatges dels models basats en Qwen i Llama?
Els models Qwen prioritzen l’escalabilitat, mentre que els basats en Llama destaquen en tasques avançades de raonament matemàtic i factual.