Qwen 2 – Actualizació del model LLM xinés
Qwen2 presenta importants millores i expansions en aquesta nova versió. La sèrie Qwen2 ofereix models preentrenados i ajustats per instruccions en cinc grandàries diferents: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B i Qwen2-72B. Aquests models han estat entrenats en dades que abasten 27 idiomes addicionals a més de l’anglès i el xinès, la qual cosa reforça les seves capacitats multilingües.
| Models | Qwen2-0.5B | Qwen2-1.5B | Qwen2-7B | Qwen2-57B-A14B | Qwen2-72B |
|---|---|---|---|---|---|
| Paràmetres | 0.49B | 1.54B | 7.07B | 57.41B | 72.71B |
| Paràmetres no emb. | 0.35B | 1.31B | 5.98B | 56.32B | 70.21B |
| GQA | Sí | Sí | Sí | Sí | Sí |
| Tie Embedding | Sí | Sí | No | No | No |
| Longitud Context | 32K | 32K | 128K | 64K | 128K |
Un dels avanços destacats és el rendiment millorat en una àmplia gamma d’avaluacions de referència, especialment en codificació i matemàtiques. A més, s’ha estès el suport de longitud de context fins a 128K tokens en els models Qwen2-7B-*Instruct i Qwen2-72B-*Instruct. Aquests models estan disponibles en plataformes com Hugging Face i ModelScope.
Tots els models Qwen2 ara inclouen Group Query Attention (GQA), la qual cosa millora la velocitat i redueix l’ús de memòria durant la inferència. Quant a la longitud del context, els models basi han estat preentrenados amb una longitud de context de 32K tokens, demostrant capacitats d’extrapolació fins a 128K en avaluacions específiques.
El rendiment multilingüe ha estat una prioritat, amb esforços significatius per a millorar tant el volum com la qualitat de les dades de preentrenament i ajust per instruccions en múltiples idiomes, incloent-hi alemany, francès, espanyol, portuguès, italià, holandès, rus, àrab, japonès, coreà, hindi, i més. S’ha treballat també a abordar el canvi de codi, millorant la competència dels models en aquest aspecte.
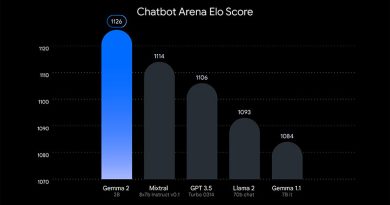
Les avaluacions comparatives mostren millores substancials en el rendiment dels models Qwen2, especialment el Qwen2-72B, que supera a models d’avantguarda com Llama-3-70B i al seu predecessor Qwen1.5-110B, malgrat tenir menys paràmetres. Aquestes avaluacions inclouen capacitats en comprensió del llenguatge natural, adquisició de coneixements, codificació, habilitats matemàtiques i competències multilingües.
El post-entrenament de Qwen2 s’ha centrat en acostar la intel·ligència del model a la humana, millorant les seves capacitats en diverses àrees i alineant les seves sortides amb els valors humans. S’han utilitzat estratègies d’alineació automatitzades i mètodes d’entrenament innovadors per a obtenir dades d’alta qualitat i diverses demostracions. Aquests esforços han millorat significativament la intel·ligència i capacitats del model.
Qwen2-72B-*Instruct ha estat avaluat exhaustivament en 16 benchmarks, demostrant un equilibri entre capacitats millorades i alineació amb valors humans. Aquest model supera significativament al seu predecessor i manté un rendiment competitiu enfront d’altres models líders. Fins i tot els models més petits de Qwen2 demostren avantatges en benchmarks específics, destacant en àrees com a codificació i mètriques relacionades amb el xinès.