Qwen2.5: Un avanç important en Models LLM
L’equip d’Alibaba ha causat enrenou a la comunitat d’IA i aprenentatge automàtic amb el llançament de la seva última sèrie de models de llenguatge gran (LLMs), la Qwen2.5. Aquesta sèrie ha impressionat per les seves capacitats millorades, obtenint resultats notables en diversos indicadors de rendiment, des de tasques de codificació fins a problemes matemàtics, passant pel seguiment d’instruccions i el suport multilingüe. Els models abasten des dels 0,5 mil milions de paràmetres fins als 72 mil milions de paràmetres, oferint solucions especialitzades com Qwen2.5-Coder i Qwen2.5-Math per a aplicacions més específiques.
Panorama General de la Sèrie Qwen2.5
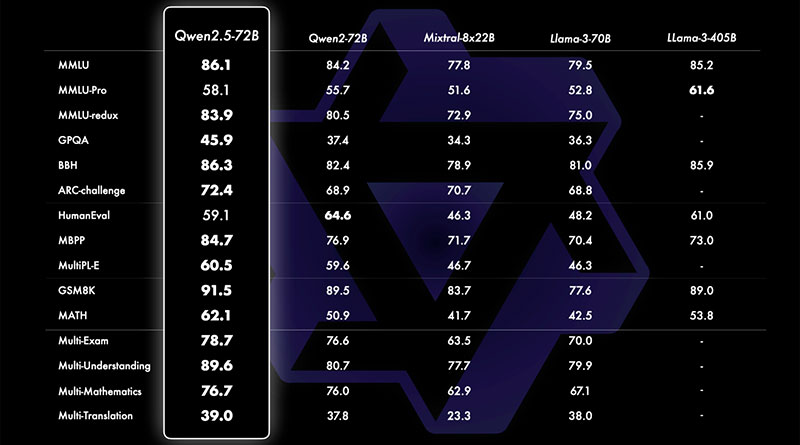
Un dels aspectes més emocionants de Qwen2.5 és la seva versatilitat i rendiment, que li permet competir directament amb alguns dels models més potents del mercat, com Llama 3.1 i Mistral Large 2. Malgrat tenir menys paràmetres en la seva variant més gran, el model Qwen2.5 de 72 mil milions de paràmetres és capaç de rivalitzar amb Llama 3.1 (405 mil milions de paràmetres) i Mistral Large 2 (123 mil milions), cosa que subratlla la fortalesa de la seva arquitectura subjacent.
Aquests models han estat entrenats amb un extens conjunt de dades de fins a 18 bilions de tokens, proporcionant un vast coneixement per a diverses tasques. En termes de rendiment, Qwen2.5 ha mostrat millores substancials en relació amb el seu predecessor, Qwen2, superant el 85% en el benchmark de MMLU (Massive Multitask Language Understanding), obtenint més de 85 punts en HumanEval i superant el 80% en el benchmark de MATH. Aquestes millores el converteixen en un dels models més capaços en àrees que requereixen raonament estructurat, resolució de problemes matemàtics i codificació.
Capacitats de Processament de Llarg Context i Suport Multilingüe
Una de les característiques més destacades de Qwen2.5 és la seva capacitat per processar contextos llargs, admetent una longitud de fins a 128,000 tokens. Aquesta capacitat és crucial per a tasques que requereixen entrades extenses i complexes, com l’anàlisi de documents legals o la generació de contingut de format llarg. A més, Qwen2.5 pot generar fins a 8,192 tokens, cosa que el converteix en una eina ideal per a la generació d’informes detallats, narratives extenses o fins i tot manuals tècnics.
Una altra característica clau d’aquesta sèrie és el seu suport per a 29 idiomes, cosa que la converteix en una eina robusta per a aplicacions multilingües. Entre els idiomes suportats s’inclouen alguns dels més parlats a nivell mundial, com el xinès, anglès, francès, espanyol, portuguès, alemany, italià, rus, japonès, coreà, vietnamita, tailandès i àrab. Aquest suport assegura que Qwen2.5 pot ser utilitzat en diversos contextos lingüístics i culturals, des de la generació de contingut fins als serveis de traducció.
Especialització: Qwen2.5-Coder i Qwen2.5-Math
Alibaba ha llançat variants especialitzades amb models base: Qwen2.5-Coder i Qwen2.5-Math. Aquests models estan dissenyats per a dominis específics com la programació i les matemàtiques, amb configuracions optimitzades per a aquests casos d’ús particulars.
- El model Qwen2.5-Coder està disponible en configuracions de 1.5 mil milions, 7 mil milions i 32 mil milions de paràmetres, i està dissenyat per a tasques de programació, cosa que el converteix en una eina poderosa per al desenvolupament de programari, la generació automatitzada de codi i altres activitats relacionades.
- D’altra banda, la variant Qwen2.5-Math està afinada específicament per al raonament matemàtic i la resolució de problemes matemàtics, i també està disponible en configuracions de 1.5 mil milions, 7 mil milions i 72 mil milions de paràmetres. Això la converteix en una opció destacada per a la recerca acadèmica, les plataformes educatives i les aplicacions científiques.
Variants Qwen2.5: 0.5B, 1.5B i 72B
Entre els models acabats de llançar, destaquen tres variants clau: Qwen2.5-0.5B, Qwen2.5-1.5B i Qwen2.5-72B. Aquestes versions cobreixen una àmplia gamma de escales de paràmetres i estan dissenyades per satisfer diferents necessitats computacionals i específiques de les tasques.
- El model Qwen2.5-0.5B amb 0.49 mil milions de paràmetres serveix com un model base per a tasques generals. Utilitza una arquitectura basada en transformadors amb Rotary Position Embeddings (RoPE), activació SwiGLU i normalització RMSNorm, combinada amb mecanismes d’atenció amb biaix QKV. Tot i que aquest model no està optimitzat per a tasques de diàleg, és capaç de manejar una varietat de tasques de processament de text i generació.
- La versió Qwen2.5-1.5B, amb 1.54 mil milions de paràmetres, es construeix sobre la mateixa arquitectura però ofereix un rendiment millorat per a tasques més complexes. Aquest model és adequat per a aplicacions que requereixen una comprensió més profunda i longituds de context més llargues, com la recerca, l’anàlisi de dades i la redacció tècnica.
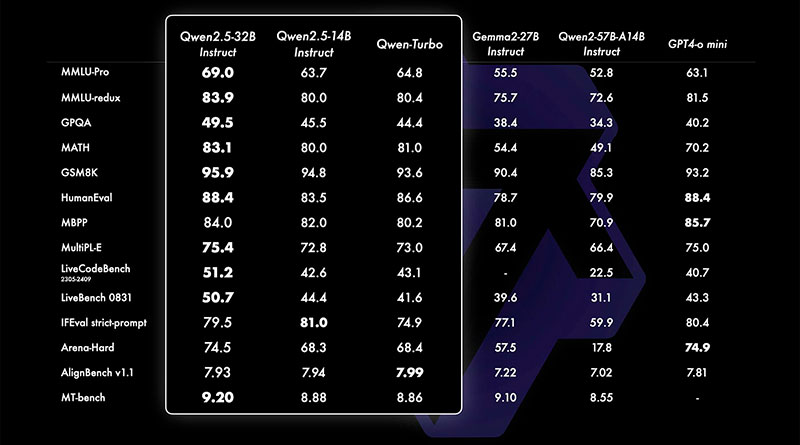
- Finalment, el model Qwen2.5-72B representa la variant de gamma alta amb 72 mil milions de paràmetres, posicionant-se com un competidor directe d’alguns dels LLMs més avançats. La seva capacitat per manejar grans volums de dades i contextos extensos el converteix en una opció ideal per a aplicacions a nivell empresarial, des de la generació de contingut fins a la intel·ligència empresarial i la < strong>recerca avançada en aprenentatge automàtic.
Característiques Arquitectòniques Clau
La sèrie Qwen 2.5 comparteix diversos avenços arquitectònics clau que fan que aquests models siguin altament eficients i adaptables:
- RoPE (Rotary Position Embeddings): permet el processament eficient d’entrades de context llarg, millorant la capacitat dels models per manejar seqüències de text extenses sense perdre coherència.
- SwiGLU (Swish-Gated Linear Units): aquesta funció d’activació millora la capacitat dels models per capturar patrons complexos en les dades, mantenint l’eficiència computacional.
- RMSNorm: una tècnica de normalització que estabilitza l’entrenament i millora els temps de convergència, fet especialment útil quan es tracta amb models més grans i conjunts de dades extensos.
- Atenció amb biaix QKV: aquest mecanisme d’atenció millora la capacitat dels models per centrar-se en la informació rellevant dins de les dades d’entrada, garantint resultats més precisos i apropiats en context.
El llançament de Qwen2.5 i les seves variants especialitzades marca un avenç significatiu en les capacitats d’IA i aprenentatge automàtic. Amb millores en el maneig de contextos llargs, suport multilingüe, seguiment d’instruccions i la generació de dades estructurades, la sèrie Qwen2.5 està destinada a jugar un paper clau en diverses indústries. Els models especialitzats, com Qwen2.5-Coder i Qwen2.5-Math, amplien encara més la seva utilitat, oferint solucions específiques per a aplicacions de codificació i matemàtiques.
S’espera que la sèrie Qwen2.5 desafii els LLMs líders com Llama 3.1 i Mistral Large 2, demostrant que l’equip d’Alibaba continua empenyent els límits en models d’IA a gran escala. Amb mides de paràmetres que van des de 0,5 mil milions fins a 72 mil milions, aquesta sèrie cobreix una àmplia gamma de casos d’ús, des de tasques lleugeres fins a aplicacions empresarials de gran envergadura. A mesura que avança la IA, models com Qwen2.5 seran fonamentals per modelar el futur de la tecnologia de llenguatge generatiu.
Preguntes i respostes:
Quins són els principals avenços que ofereix la sèrie Qwen2.5?
La sèrie Qwen2.5 ofereix importants millores en àrees com la codificació, les matemàtiques, el seguiment d’instruccions i el suport multilingüe. A més, la seva capacitat per manejar contextos llargs i generar grans quantitats de text el converteix en una eina versàtil i eficient per a diverses aplicacions.
Com es compara el model Qwen2.5 amb altres models de llenguatge gran?
El model Qwen2.5, especialment la seva versió de 72 mil milions de paràmetres, pot competir amb alguns dels models més avançats, com Llama 3.1 i Mistral Large 2, tot i tenir menys paràmetres. Això es deu a l’optimització de la seva arquitectura subjacent, que permet un rendiment de nivell alt amb un nombre menor de paràmetres.
Quines característiques fan que Qwen2.5 sigui adequat per a tasques de llarg context?
El model Qwen2.5 suporta una longitud de context de fins a 128,000 tokens, cosa que el fa ideal per processar entrades llargues i complexes, com documents legals o la generació de contingut extens. A més, pot generar fins a 8,192 tokens, facilitant la creació d’informes detallats o manuals tècnics.
Quines variants especialitzades inclou la sèrie Qwen2.5 i per a què estan dissenyades?
La sèrie Qwen2.5 inclou dues variants especialitzades: Qwen2.5-Coder i Qwen2.5-Math. Qwen2.5-Coder està optimitzat per a tasques de programació i generació de codi, mentre que Qwen2.5-Math està dissenyat per a raonament matemàtic i resolució de problemes matemàtics.
Quines característiques arquitectòniques clau té la sèrie Qwen2.5?
Entre les característiques arquitectòniques destacades de Qwen2.5 s’inclouen Rotary Position Embeddings (RoPE) per al processament eficient de contextos llargs, l’activació SwiGLU per capturar patrons complexos de manera eficient, i RMSNorm, una tècnica de normalització que millora l’estabilitat i els temps de convergència durant l’entrenament del model.







