OpenAI llança nous models d’àudio
OpenAI ha anunciat recentment el llançament de nous models d’àudio a la seva API, dissenyats per millorar la interacció entre humans i agents d’intel·ligència artificial mitjançant l’ús del llenguatge parlat. Aquests avanços inclouen models de transcripció de veu a text i de síntesi de text a veu, que ofereixen una major precisió i personalització en diverses aplicacions.
Nous models de transcripció de veu a text
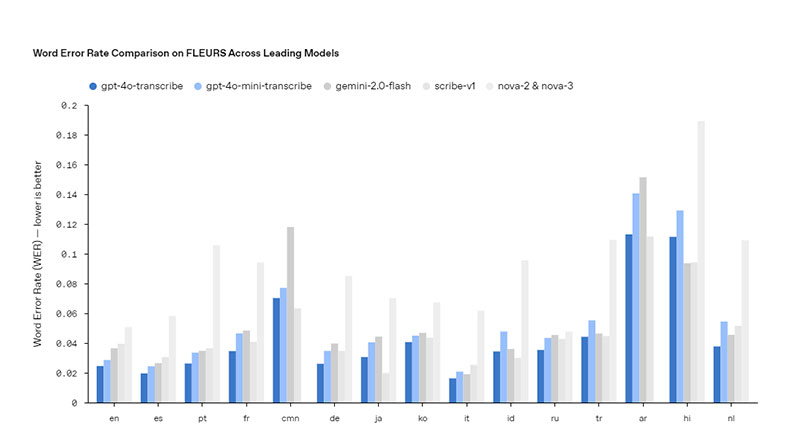
OpenAI ha introduït dos models principals per a la transcripció d’àudio: gpt-4o-transcribe i gpt-4o-mini-transcribe. Aquests models presenten millores significatives en la taxa d’error de paraules (WER) i en el reconeixement de múltiples idiomes, superant models anteriors com Whisper. Gràcies a innovacions en l’aprenentatge per reforç i a l’entrenament amb conjunts de dades d’àudio diversos i d’alta qualitat, aquests models són capaços de captar millor els matisos de la parla, reduir errors de reconeixement i augmentar la fiabilitat de les transcripcions, fins i tot en escenaris desafiants amb accents marcats, entorns sorollosos o variacions en la velocitat de la parla.
Nou model de síntesi de text a veu
A més dels models de transcripció, OpenAI ha llançat el model gpt-4o-mini-tts, que permet convertir text en veu amb un alt grau de personalització. Per primera vegada, els desenvolupadors poden instruir el model no només sobre què dir, sinó també sobre com dir-ho, permetent que la veu generada adopti tonalitats específiques, com la d’un agent d’atenció al client empàtic o la d’un narrador de contes creatiu. Aquesta capacitat obre una nova dimensió de personalització per a agents de veu, millorant l’experiència de l’usuari en aplicacions com centres d’atenció al client, narracions i més.
Innovacions tècniques darrere dels models
Els avanços en aquests models d’àudio es basen en diverses innovacions tècniques clau:
- Entrenament amb dades d’àudio autèntiques: Els models s’han entrenat extensament amb conjunts de dades especialitzats en àudio, cosa que ha estat crucial per optimitzar-ne el rendiment i la comprensió dels matisos de la parla.
- Metodologies avançades de destil·lació: S’han millorat les tècniques de destil·lació, permetent transferir coneixements dels models d’àudio més grans a models més petits i eficients, mantenint una alta qualitat conversacional i capacitat de resposta.
- Paradigma d’aprenentatge per reforç: En els models de transcripció, s’ha integrat un enfocament intensiu d’aprenentatge per reforç, elevant la precisió de la transcripció a nivells capdavanters i reduint errors, fet que els fa especialment competitius en escenaris complexos de reconeixement de veu.
Disponibilitat de l’API
Aquests nous models d’àudio estan disponibles per a tots els desenvolupadors a través de l’API d’OpenAI. Per a aquells que ja estan construint experiències conversacionals amb models basats en text, la incorporació dels models de transcripció i síntesi de veu és el camí més senzill per desenvolupar un agent de veu. OpenAI també ha llançat una integració amb el Agents SDK, que simplifica aquest procés de desenvolupament. Per a experiències de veu a veu amb baixa latència, es recomana utilitzar els models de speech-to-speech disponibles a l’API en temps real.
Perspectives futures
De cara al futur, OpenAI preveu continuar invertint en la millora de la intel·ligència i la precisió dels seus models d’àudio. A més, s’exploraran maneres perquè els desenvolupadors puguin incorporar les seves pròpies veus personalitzades, creant experiències encara més adaptades a les necessitats específiques dels usuaris, sempre alineades amb els estàndards de seguretat de la companyia. OpenAI també està compromesa a mantenir converses amb legisladors, investigadors, desenvolupadors i creatius sobre els reptes i oportunitats que presenten les veus sintètiques. Aquestes iniciatives busquen fomentar aplicacions innovadores i creatives utilitzant les capacitats d’àudio millorades.
Preguntes i Respostes
Quines millores ofereixen els nous models de transcripció d’OpenAI?
Els models gpt-4o-transcribe i gpt-4o-mini-transcribe presenten millores significatives en la taxa d’error de paraules i en el reconeixement de múltiples idiomes, superant models anteriors com Whisper. Són capaços de captar millor els matisos de la parla, reduir errors i augmentar la fiabilitat de les transcripcions, fins i tot en condicions desafiants.
Com permet el model gpt-4o-mini-tts personalitzar la síntesi de veu?
El model gpt-4o-mini-tts permet als desenvolupadors instruir no només què dir, sinó també com dir-ho, adaptant la veu generada a tonalitats específiques, com la d’un agent d’atenció al client empàtic o un narrador creatiu.
Com poden els desenvolupadors accedir a aquests nous models d’àudio?
Els desenvolupadors poden accedir als nous models d’àudio a través de l’API d’OpenAI, que inclou integracions com el Agents SDK per facilitar el desenvolupament d’agents de veu personalitzats.
Quins plans té OpenAI per al futur dels seus models d’àudio?
OpenAI té la intenció de continuar millorant la intel·ligència i la precisió dels seus models d’àudio, explorant formes perquè els desenvolupadors incorporin veus personalitzades i participant en converses sobre els reptes i oportunitats de les veus sintètiques.