DiffusionGemma: modelo de texto hasta 4 veces más rápido
Descubriendo DiffusionGemma: un modelo de generación de texto innovador
En el mundo actual de la inteligencia artificial, la velocidad es un factor clave. Google ha lanzado DiffusionGemma, un modelo experimental que promete generar texto hasta 4 veces más rápido que los modelos tradicionales. Utilizando una innovadora técnica de difusión, este modelo se diseñó específicamente para aplicaciones interactivas que requieren respuestas rápidas en sistemas locales.
¿Qué hace especial a DiffusionGemma?
A diferencia de los modelos tradicionales que generan texto de manera secuencial, DiffusionGemma produce bloques de texto completos simultáneamente. Esto es gracias a su arquitectura única de Mixture of Experts (MoE), que activa solamente una fracción de sus parámetros durante el procesamiento, optimizando así la eficiencia del hardware.
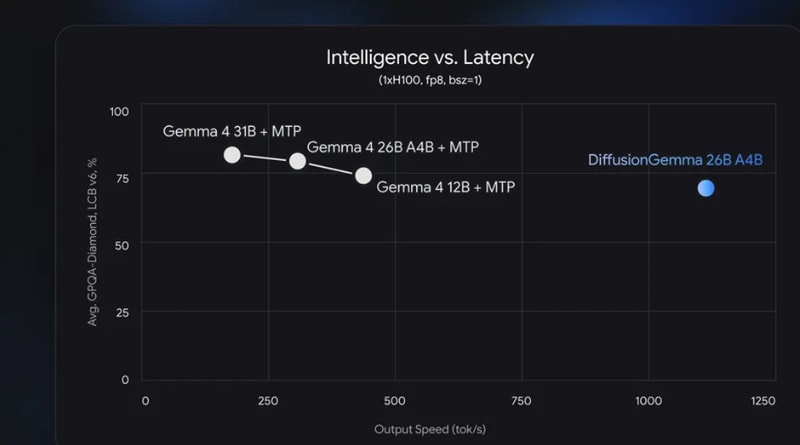
- Inferencia rápida: Genera más de 1000 tokens por segundo en GPUs dedicadas como la NVIDIA H100.
- Huella de hardware accesible: Opera cómodamente en GPUs de gama alta gracias a la activación de solo 3.8 billones de sus 26 billones de parámetros.
- Atención bidireccional: Permite procesar múltiples tokens en paralelo, promoviendo tareas complejas como la edición de texto o la infusión de códigos.
- Autocorrección inteligente: Capaz de refinar su salida en tiempo real, evaluando bloques de texto completos.
- Estado experimental: Aunque es veloz, su calidad de salida puede no alcanzar la de los modelos usados en producción, como el Gemma 4 estándar.

¿Por qué optar por la difusión en generación de texto?
La idea de utilizar difusión en la generación de texto no es nueva, pero DiffusionGemma ha hecho posible aplicarla en modelos de gran escala. Este enfoque contrasta con los modelos tradicionales donde la generación token a token deja subutilizado el hardware local, llevando la computación a un nivel más eficiente. Este modelo opera como una imprenta que genera textos complejos de manera simultánea, un avance significativo para aplicaciones que se ejecutan localmente.
Cómo funciona la difusión de texto
El proceso de generación de texto de DiffusionGemma se asemeja al de los generadores de imágenes por IA:
| Etapa del proceso | Descripción |
|---|---|
| El lienzo | Inicia con tokens de marcador de posición aleatorios. |
| Refinamiento iterativo | Mejora continuamente el texto fijando tokens correctos como contexto. |
| Pulido final | Converge en un texto de alta calidad. |
Preguntas y respuestas
¿Quiénes pueden beneficiarse de DiffusionGemma?
Desarrolladores y científicos que necesiten rapidez en aplicaciones interactivas, como edición de texto en tiempo real o generación de códigos complejos.
¿Cómo pueden los usuarios comenzar a usar DiffusionGemma?
Los usuarios pueden descargar los pesos del modelo desde plataformas como Hugging Face, e integrarlo utilizando guías y herramientas específicas para su hardware y necesidades.
¿Cuáles son las limitaciones de DiffusionGemma?
Aunque es extremadamente rápido, no alcanza la calidad de salida de otros modelos más enfocados en la precisión como Gemma 4. Es ideal para tareas donde la velocidad es más crítica que la perfecta calidad del texto generado.