Florence-2, modelo visión de Microsoft
Florence-2 es un modelo de visión-lenguaje de código abierto desarrollado por Microsoft y lanzado bajo la licencia MIT. A pesar de su tamaño reducido, demuestra fuertes capacidades de cero-shot y afinación fina en tareas como la descripción de imágenes, detección de objetos, asignación de significados y segmentación. Este modelo se destaca por su rendimiento comparable a modelos mucho más grandes, como Kosmos-2, gracias al uso del extenso conjunto de datos FLD-5B, que incluye 126 millones de imágenes y 5,4 mil millones de anotaciones visuales.
Florence-2 aborda la diversidad de tareas de visión unificando la representación y entrenando un solo modelo capaz de ejecutar más de diez tareas, en lugar de una serie de modelos separados. Este enfoque requiere un nuevo conjunto de datos, por lo que se creó el FLD-5B automatizando el proceso con modelos especializados existentes. FLD-5B, aunque aún no está disponible públicamente, incluye cajas, máscaras y diferentes niveles de descripciones, usando imágenes de otros conjuntos de datos de visión por computadora.
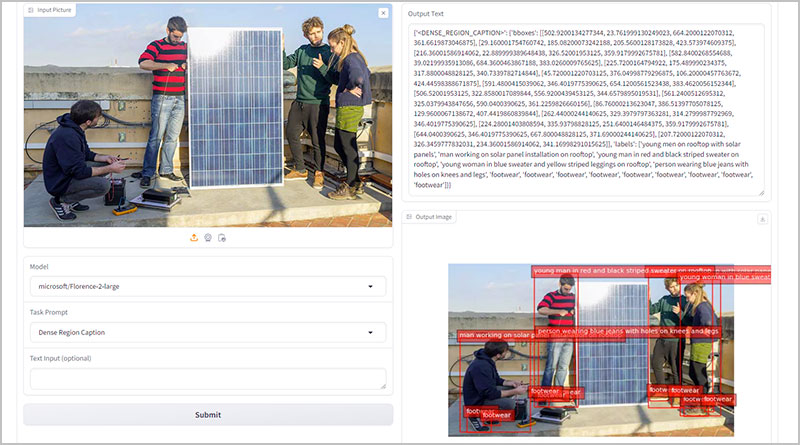
La arquitectura del modelo toma imágenes y prompts de tareas como entrada, generando los resultados deseados en formato de texto. Utiliza un codificador de visión DaViT para convertir imágenes en incrustaciones de tokens visuales, que se concatenan con incrustaciones de texto generadas por BERT y se procesan mediante un codificador-decodificador multimodal basado en transformers. Para tareas específicas de regiones, se añaden tokens de ubicación representando coordenadas cuantificadas al vocabulario del tokenizador.
Florence-2 es más pequeño y preciso que sus predecesores, con dos versiones: Florence-2-base y Florence-2-large, con 0.23 mil millones y 0.77 mil millones de parámetros respectivamente. Esto permite su implementación incluso en dispositivos móviles. A pesar de su tamaño, Florence-2 obtiene mejores resultados de cero-shot que Kosmos-2 en todos los benchmarks, a pesar de que Kosmos-2 tiene 1.6 mil millones de parámetros.
El modelo ofrece resultados destacados en tareas como asignación de significados visual, OCR con región y detección de objetos de vocabulario abierto. Florence-2 representa un avance significativo en los modelos de visión-lenguaje al combinar una arquitectura ligera con capacidades robustas, haciendo que sea altamente accesible y versátil para aplicaciones del mundo real, especialmente en dispositivos con recursos limitados.