OpenAI lanza GPT5.2
El anuncio de GPT-5.2 de OpenAI no es solo una actualización cualquiera. Se trata de una jugada muy calculada que busca defender su posición dominante en el mundo de la inteligencia artificial. Este nuevo modelo, lanzado en tres versiones distintas —Instant, Thinking y Pro—, se centra en mejorar de forma significativa el rendimiento en el trabajo profesional, la capacidad de razonamiento en textos muy largos y la generación de código. Esto se debe, en gran parte, a la intensa competencia de otros gigantes de la tecnología como Google con su modelo Gemini 3.
La estrategia detrás del nuevo gpt-5.2
Este lanzamiento se produce en un momento de gran presión para OpenAI. Sus rivales han estado logrando avances importantes, lo que ha provocado una respuesta interna urgente. La empresa se ha visto obligada a recuperar el liderazgo en las métricas clave de rendimiento, especialmente después de observar una disminución en el tráfico de su popular herramienta ChatGPT y una ligera pérdida de cuota de mercado.
A diferencia de versiones anteriores que buscaban sorprender con funciones totalmente nuevas, GPT-5.2 está pensado para la fiabilidad en el entorno empresarial. El foco está puesto en la productividad y la eficiencia, buscando ofrecer una herramienta que genere un valor económico real y medible para empresas y profesionales. Esta dirección está marcada por la necesidad de justificar las enormes inversiones en infraestructura y competir con ecosistemas integrados de la competencia.
Variantes de gpt-5.2: una opción para cada necesidad
Para cubrir las diferentes demandas del mercado, OpenAI ha segmentado su oferta con tres versiones específicas, permitiendo a los usuarios elegir el nivel de capacidad que mejor se adapte a su trabajo y presupuesto.
Versión instantánea (instant)
Diseñada para ser la más rápida y eficiente en tareas sencillas. Prioriza la velocidad de respuesta, siendo ideal para búsquedas rápidas, traducciones o la redacción de textos cortos.
Versión de razonamiento (thinking)
Esta es la versión equilibrada y el núcleo de las mejoras. Está pensada para trabajos complejos que requieren un razonamiento más profundo, como la programación, el análisis de grandes documentos, o la planificación de proyectos con múltiples pasos.
Versión profesional (pro)
La opción más potente y precisa. Se reserva para la resolución de problemas muy difíciles donde la exactitud es fundamental. Es la versión pensada para aplicaciones empresariales críticas, investigación compleja o análisis financieros.
Avances técnicos que marcan la diferencia
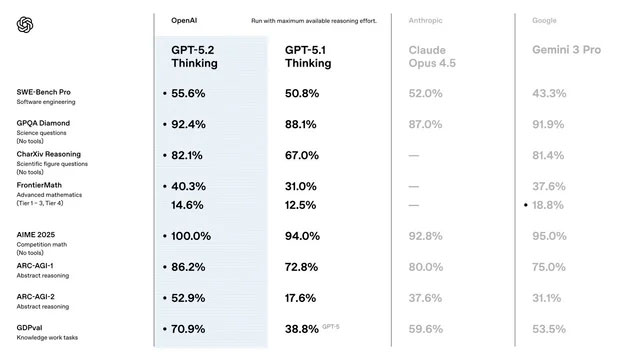
Los datos técnicos que acompañan al lanzamiento son impresionantes. En el benchmark GDPval, que evalúa tareas de 44 profesiones, la versión Thinking iguala o supera el rendimiento de un experto humano en un 70,9% de los casos. Esto es un salto significativo comparado con modelos anteriores. Además, ha demostrado mejoras notables en áreas clave:
- Generación de código: Alcanza un 55,6% de precisión en la corrección de errores de código reales (SWE-Bench Pro), un dato muy importante para los desarrolladores.
- Razonamiento abstracto: Su capacidad para resolver problemas novedosos ha mejorado sustancialmente, pasando del 17,6% a un 52,9% en las pruebas de ARC-AGI 2.
- Manejo de contexto largo: El modelo puede analizar informes, contratos o bases de código completas sin perder el hilo, admitiendo, según fuentes, hasta 1,5 millones de tokens.
Estos números sugieren una herramienta más robusta y menos propensa a errores, con la tasa de fallos reducida del 8,8% al 6,2% en general, y una disminución en las llamadas “alucinaciones” o respuestas incorrectas.
La recepción de los usuarios: escepticismo y críticas
A pesar de los resultados brillantes en las pruebas de laboratorio, una parte importante de la comunidad de usuarios avanzados y desarrolladores ha recibido GPT-5.2 con un notable escepticismo. Existe una sensación de «fatiga de benchmarks», donde los usuarios no creen que las métricas de prueba se traduzcan en una mejor experiencia diaria.
Una crítica recurrente es la percepción de que el modelo se ha vuelto excesivamente «corporativo» o «aprobado por RRHH». Los usuarios notan una pérdida de creatividad y una personalidad más restrictiva, orientada a la seguridad y la productividad empresarial, lo que muchos perciben como una limitación. La desconfianza también proviene de experiencias pasadas donde modelos anteriores parecieron «debilitarse» después de su lanzamiento (los llamados «nerfeos»), supuestamente para reducir costos operativos. Esto ha generado una crítica hacia los filtros de seguridad que, a veces, interrumpen flujos de trabajo legítimos.
La disponibilidad del modelo es escalonada, empezando por los suscriptores de pago de ChatGPT (Plus, Teams, Enterprise) y a través de la API para desarrolladores, con una estructura de precios que enfatiza el uso profesional y los altos costos para la versión Pro.
Preguntas y respuestas frecuentes sobre GPT-5.2
¿Qué es gpt-5.2 y cuál es su enfoque principal?
GPT-5.2 es la última actualización de los modelos de inteligencia artificial de OpenAI. Su enfoque principal es mejorar el rendimiento, la fiabilidad y el razonamiento en tareas profesionales y de codificación, buscando generar un valor económico claro para las empresas.
¿Cuáles son las tres variantes de gpt-5.2?
Las tres variantes son: Instant, optimizada para la velocidad en tareas sencillas; Thinking, equilibrada para trabajos complejos y razonamiento profundo; y Pro, la versión más potente y precisa para problemas críticos.
¿Por qué algunos usuarios son escépticos sobre su lanzamiento?
El escepticismo se debe a la llamada «fatiga de benchmarks», que es la desconfianza de que los altos resultados en pruebas de laboratorio se traduzcan en una mejor experiencia de uso diario. También influye la percepción de que el modelo es ahora más «corporativo» y menos creativo debido a filtros de seguridad más restrictivos, además de la desconfianza por los ajustes de rendimiento no comunicados en versiones anteriores.
¿Cómo ha mejorado gpt-5.2 en la generación de código?
En el benchmark SWE-Bench Pro, que evalúa la capacidad de corregir errores en código real, GPT-5.2 ha logrado una precisión del 55,6%, un aumento notable que lo acerca a un nivel muy útil para los desarrolladores de software.