Gemma 3n: IA en Dispositivos
La inteligencia artificial ha dado un paso agigantado con la llegada de Gemma 3n, el último modelo de IA generativa de código abierto de Google. Este innovador desarrollo está diseñado para funcionar de manera eficiente en los dispositivos que usamos a diario, como teléfonos, computadoras portátiles y tabletas, incluso aquellos con recursos de memoria limitados, tan solo 2GB de RAM. La capacidad de Gemma 3n para procesar entradas de audio, visuales y de texto, y generar respuestas de texto, lo convierte en una herramienta sumamente versátil.
IA Optimizado para Dispositivos Cotidianos
El principal objetivo de Gemma 3n es llevar las capacidades avanzadas de la IA directamente a las manos de los usuarios. Esto significa que la inteligencia artificial ya no dependerá de una conexión constante a la nube, lo que se traduce en experiencias más rápidas, con un menor consumo de energía y una mayor privacidad. Este enfoque en la «IA en el dispositivo» es crucial para democratizar el acceso a tecnologías de vanguardia.
Multimodalidad: Un Paso Adelante en la Interacción con la IA
Una de las características más destacadas de Gemma 3n es su diseño inherentemente multimodal. Esto le permite comprender y procesar una combinación de datos, incluyendo imágenes, audio, video y texto, y luego generar respuestas coherentes en formato de texto. Esta capacidad lo posiciona como una herramienta excepcionalmente flexible para una amplia variedad de aplicaciones, desde asistentes de voz inteligentes hasta sistemas de análisis de contenido multimedia.
Eficiencia y Flexibilidad de Recursos
A pesar de contar con un número de parámetros que lo clasifica como un modelo más grande (versiones de 5B y 8B), las innovaciones arquitectónicas de Gemma 3n le permiten operar con una huella de memoria mucho menor. Su eficiencia es tal que se compara con modelos de 2B y 4B, lo cual es fundamental para su implementación en dispositivos con hardware restringido. Esta optimización de recursos es un diferenciador clave en el mercado de la IA.
Características y Capacidades Clave de Gemma 3n
Gemma 3n ha sido meticulosamente optimizado para su uso en una amplia gama de dispositivos cotidianos, incluyendo teléfonos inteligentes, laptops y tablets. Es notable su habilidad para operar en un smartphone con apenas 2GB de RAM, lo que amplía significativamente su accesibilidad.
Procesamiento Multimodal Nativo
Este modelo se distingue por su soporte nativo para entradas y salidas de texto, imágenes, audio y video. En el ámbito del audio, Gemma 3n procesa datos de sonido para tareas como el reconocimiento de voz, la traducción y el análisis de información auditiva. Para ello, incorpora un codificador de audio avanzado basado en el Universal Speech Model (USM), facilitando el reconocimiento automático de voz (ASR) y la traducción automática de voz (AST).
En cuanto a la visión, integra el codificador de alto rendimiento MobileNet-V5, que mejora drásticamente la velocidad y precisión en el procesamiento de datos visuales. La versión MobileNet-V5-300M puede procesar hasta 60 cuadros por segundo en un Google Pixel, lo que representa un aumento de velocidad de 13x con cuantificación (o 6.5x sin) y una reducción del 46% en el número de parámetros en comparación con modelos anteriores.
Cobertura Lingüística y Contexto Ampliado
Gemma 3n presume de amplias capacidades lingüísticas, habiendo sido entrenado con más de 140 idiomas para texto y ofreciendo una comprensión multimodal en 35 idiomas. Además, su considerable contexto de tokens de 32,000 le permite analizar grandes volúmenes de datos de manera eficiente.
Mejoras en la Calidad y el Rendimiento
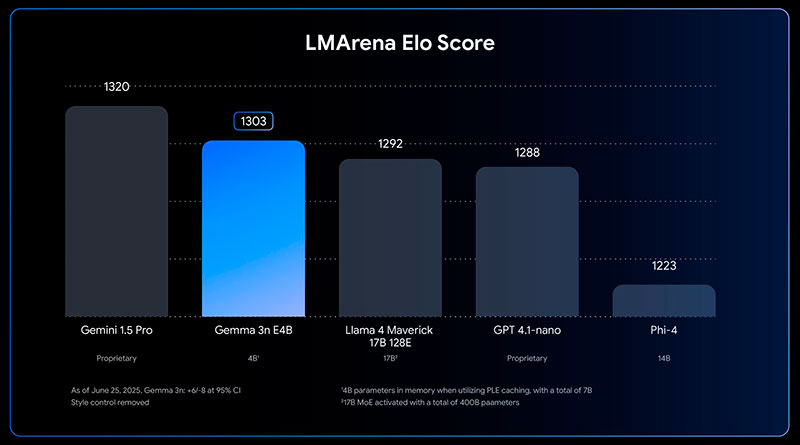
El modelo ofrece mejoras significativas en áreas como el multilingüismo, las matemáticas, la codificación y el razonamiento. La versión E4B de Gemma 3n ha logrado una puntuación en LMArena superior a 1300, convirtiéndose en el primer modelo con menos de 10 mil millones de parámetros en alcanzar este estándar.
Para optimizar su rendimiento y el uso de memoria en dispositivos, Gemma 3n incorpora varias innovaciones arquitectónicas revolucionarias.
Innovaciones Arquitectónicas para la Eficiencia
Arquitectura MatFormer (Matryoshka Transformer)
La arquitectura Matryoshka Transformer permite la activación selectiva de los parámetros del modelo según la solicitud, lo que reduce el costo de procesamiento y los tiempos de respuesta. Esta arquitectura novedosa es un transformador anidado diseñado para la inferencia elástica. Un modelo más grande, como el E4B, contiene versiones más pequeñas y completamente funcionales de sí mismo (E2B). Esto posibilita a los desarrolladores descargar y utilizar modelos pre-extraídos para una inferencia más rápida o crear tamaños personalizados ajustando parámetros internos. También prepara el camino para la ejecución elástica, donde un único modelo desplegado podría cambiar dinámicamente entre rutas de inferencia E4B y E2B en tiempo real.
Almacenamiento en Caché de PLE (Per-Layer Embeddings)
Los parámetros de incorporación por capa (PLE) de estos modelos se pueden almacenar en caché en un almacenamiento local y rápido, lo que reduce los costos de ejecución de la memoria del modelo. Esto permite que una parte significativa de estos parámetros se cargue y compute eficientemente en la CPU, de modo que solo los pesos del transformador central necesiten estar en la memoria del acelerador, que es más restringida. Por ejemplo, el modelo E2B puede operar con solo aproximadamente 2 mil millones de parámetros cargados en su acelerador, a pesar de tener un recuento total de 5 mil millones.
Carga de Parámetros Condicionales y KV Cache Sharing
La carga de parámetros condicionales permite omitir la carga de ciertos parámetros en la memoria, como los de audio o visuales, reduciendo así la carga de memoria. Estos pueden cargarse dinámicamente en tiempo de ejecución si el dispositivo cuenta con los recursos. Además, la función KV Cache Sharing optimiza el manejo de la fase inicial de procesamiento de entrada, compartiendo directamente las claves y valores de la capa intermedia de la atención local y global con todas las capas superiores, lo que ofrece una notable mejora de 2 veces en el rendimiento de «prefill» en comparación con Gemma 3 4B.
Disponibilidad y Soporte para Desarrolladores
Gemma 3n se distribuye como código abierto y con una licencia que permite su uso comercial responsable. Esto fomenta su adopción, ajuste y despliegue por parte de la comunidad de desarrolladores. Los modelos están disponibles para experimentación directa en Google AI Studio, y sus pesos se pueden descargar desde Hugging Face y Kaggle. Además, cuenta con un amplio soporte para herramientas y plataformas populares, incluyendo Hugging Face Transformers, llama.cpp, Google AI Edge, Ollama, MLX, Docker, transformers.js, NVIDIA NeMo Framework, Unsloth y LMStudio, entre otros. Las opciones de implementación incluyen Google GenAI API, Vertex AI, SGLang, vLLM y NVIDIA API Catalog. Para impulsar la innovación, Google ha lanzado el «Gemma 3n Impact Challenge» con 150.000 dólares en premios.
Preguntas y Respuestas sobre Gemma 3n
¿Qué es Gemma 3n?
Gemma 3n es el modelo de inteligencia artificial generativa de código abierto más reciente de Google, diseñado para operar eficientemente en dispositivos cotidianos como teléfonos inteligentes, computadoras portátiles y tabletas, incluso con recursos de memoria limitados.
¿Qué significa que Gemma 3n sea «multimodal»?
La multimodalidad de Gemma 3n implica que puede procesar y comprender una combinación de datos de imagen, audio, video y texto como entrada, y generar respuestas en formato de texto.
¿Qué innovaciones arquitectónicas tiene Gemma 3n para su eficiencia?
Gemma 3n incorpora innovaciones como la arquitectura MatFormer (Matryoshka Transformer) y el almacenamiento en caché de Per-Layer Embeddings (PLE), que le permiten una flexibilidad computacional y una eficiencia de memoria sin precedentes para modelos de su escala.
¿En qué tipo de dispositivos puede funcionar Gemma 3n?
Está optimizado para su uso en dispositivos cotidianos como teléfonos, laptops y tablets, y puede ejecutarse en un smartphone con tan solo 2GB de RAM.
¿Gemma 3n es de código abierto y tiene soporte para desarrolladores?
Sí, Gemma 3n se proporciona con pesos abiertos y licencia para uso comercial responsable. Además, cuenta con amplio soporte para herramientas y plataformas populares, y Google ha lanzado un desafío para fomentar su desarrollo.