Qwen2.5: Un avance importante en Modelos LLM
El equipo de Alibaba ha causado revuelo en la comunidad de IA y aprendizaje automático con el lanzamiento de su última serie de modelos de lenguaje grande (LLMs), la Qwen2.5. Esta serie ha impresionado por sus capacidades mejoradas, obteniendo resultados notables en varios indicadores de rendimiento, desde tareas de codificación hasta problemas matemáticos, pasando por el seguimiento de instrucciones y el soporte multilingüe. Los modelos abarcan desde los 0.5 mil millones de parámetros hasta los 72 mil millones de parámetros, ofreciendo soluciones especializadas como Qwen2.5-Coder y Qwen2.5-Math para aplicaciones más específicas.
Panorama General de la Serie Qwen2.5
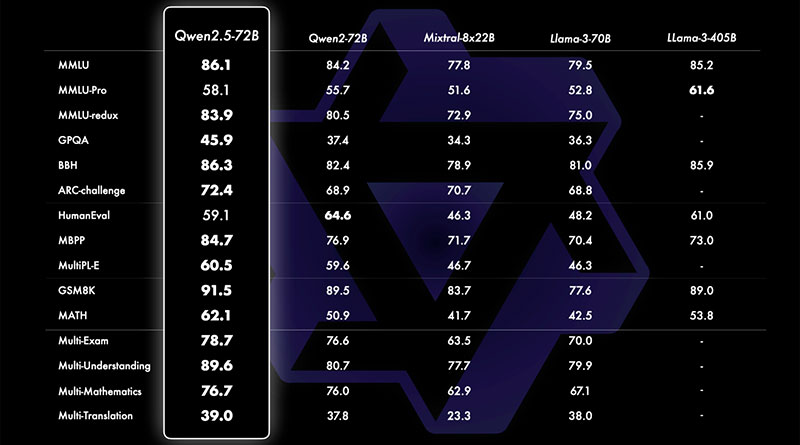
Uno de los aspectos más emocionantes de Qwen2.5 es su versatilidad y rendimiento, lo que le permite competir directamente con algunos de los modelos más potentes del mercado, como Llama 3.1 y Mistral Large 2. A pesar de tener menos parámetros en su variante más grande, el modelo Qwen2.5 de 72 mil millones de parámetros es capaz de rivalizar con Llama 3.1 (405 mil millones de parámetros) y Mistral Large 2 (123 mil millones), lo que subraya la fortaleza de su arquitectura subyacente.
Estos modelos han sido entrenados con un extenso conjunto de datos de hasta 18 billones de tokens, proporcionando un vasto conocimiento para diversas tareas. En términos de rendimiento, Qwen2.5 ha mostrado mejoras sustanciales en relación con su predecesor, Qwen2, superando el 85% en el benchmark de MMLU (Massive Multitask Language Understanding), obteniendo más de 85 puntos en HumanEval y superando el 80% en el benchmark de MATH. Estas mejoras lo convierten en uno de los modelos más capaces en áreas que requieren razonamiento estructurado, resolución de problemas matemáticos y codificación.
Capacidades de Procesamiento de Largo Contexto y Soporte Multilingüe
Una de las características más destacadas de Qwen2.5 es su capacidad para procesar contextos largos, admitiendo una longitud de hasta 128,000 tokens. Esta capacidad es crucial para tareas que requieren entradas extensas y complejas, como el análisis de documentos legales o la generación de contenido de formato largo. Además, Qwen2.5 puede generar hasta 8,192 tokens, lo que lo convierte en una herramienta ideal para la generación de informes detallados, narrativas extensas o incluso manuales técnicos.
Otra característica clave de esta serie es su soporte para 29 idiomas, lo que lo convierte en una herramienta robusta para aplicaciones multilingües. Entre los idiomas soportados se incluyen algunos de los más hablados a nivel mundial, como el chino, inglés, francés, español, portugués, alemán, italiano, ruso, japonés, coreano, vietnamita, tailandés y árabe. Este soporte asegura que Qwen2.5 puede ser utilizado en diversos contextos lingüísticos y culturales, desde la generación de contenido hasta los servicios de traducción.
Especialización: Qwen2.5-Coder y Qwen2.5-Math
Alibaba ha lanzado variantes especializadas con modelos base: Qwen2.5-Coder y Qwen2.5-Math. Estos modelos están diseñados para dominios específicos como la programación y las matemáticas, con configuraciones optimizadas para estos casos de uso particulares.
- El modelo Qwen2.5-Coder está disponible en configuraciones de 1.5 mil millones, 7 mil millones y 32 mil millones de parámetros, y está diseñado para tareas de programación, lo que lo convierte en una herramienta poderosa para el desarrollo de software, la generación automatizada de código y otras actividades relacionadas.
- Por otro lado, la variante Qwen2.5-Math está afinada específicamente para el razonamiento matemático y la resolución de problemas matemáticos, y también está disponible en configuraciones de 1.5 mil millones, 7 mil millones y 72 mil millones de parámetros. Esto la convierte en una opción destacada para la investigación académica, las plataformas educativas y las aplicaciones científicas.
Variantes Qwen2.5: 0.5B, 1.5B y 72B
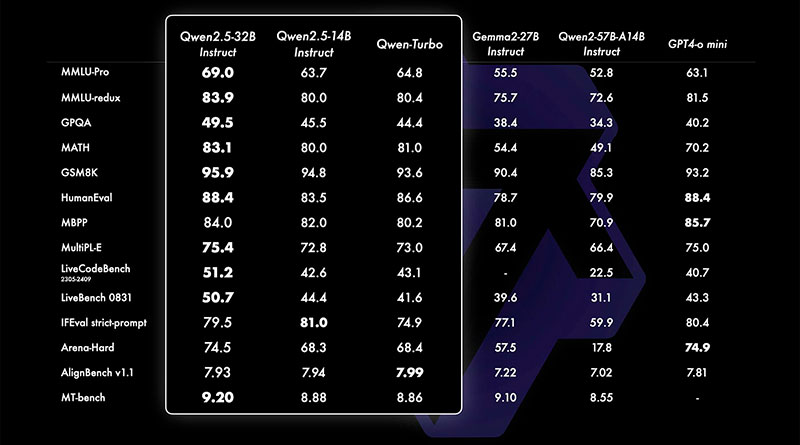
Entre los modelos recién lanzados, destacan tres variantes clave: Qwen2.5-0.5B, Qwen2.5-1.5B y Qwen2.5-72B. Estas versiones cubren una amplia gama de escalas de parámetros y están diseñadas para satisfacer diferentes necesidades computacionales y específicas de las tareas.
- El modelo Qwen2.5-0.5B con 0.49 mil millones de parámetros sirve como un modelo base para tareas generales. Utiliza una arquitectura basada en transformadores con Rotary Position Embeddings (RoPE), activación SwiGLU y normalización RMSNorm, combinada con mecanismos de atención con sesgo QKV. Si bien este modelo no está optimizado para tareas de diálogo, es capaz de manejar una variedad de tareas de procesamiento de texto y generación.
- La versión Qwen2.5-1.5B, con 1.54 mil millones de parámetros, construye sobre la misma arquitectura pero ofrece un rendimiento mejorado para tareas más complejas. Este modelo es adecuado para aplicaciones que requieren una comprensión más profunda y longitudes de contexto más largas, como la investigación, el análisis de datos y la redacción técnica.
- Finalmente, el modelo Qwen2.5-72B representa la variante de gama alta con 72 mil millones de parámetros, posicionándose como un competidor directo de algunos de los LLMs más avanzados. Su capacidad para manejar grandes volúmenes de datos y contextos extensos lo convierte en una opción ideal para aplicaciones a nivel empresarial, desde la generación de contenido hasta la inteligencia empresarial y la investigación avanzada en aprendizaje automático.
Características Arquitectónicas Clave
La serie Qwen 2.5 comparte varios avances arquitectónicos clave que hacen que estos modelos sean altamente eficientes y adaptables:
- RoPE (Rotary Position Embeddings): permite el procesamiento eficiente de entradas de contexto largo, mejorando la capacidad de los modelos para manejar secuencias de texto extensas sin perder coherencia.
- SwiGLU (Swish-Gated Linear Units): esta función de activación mejora la capacidad de los modelos para capturar patrones complejos en los datos, manteniendo la eficiencia computacional.
- RMSNorm: una técnica de normalización que estabiliza el entrenamiento y mejora los tiempos de convergencia, lo que es especialmente útil cuando se trata con modelos más grandes y conjuntos de datos extensos.
- Atención con sesgo QKV: este mecanismo de atención mejora la capacidad de los modelos para enfocarse en la información relevante dentro de los datos de entrada, garantizando resultados más precisos y apropiados en contexto.
El lanzamiento de Qwen2.5 y sus variantes especializadas marca un avance significativo en las capacidades de IA y aprendizaje automático. Con mejoras en el manejo de contextos largos, soporte multilingüe, seguimiento de instrucciones y la generación de datos estructurados, la serie Qwen2.5 está destinada a desempeñar un papel clave en varias industrias. Los modelos especializados, como Qwen2.5-Coder y Qwen2.5-Math, amplían aún más su utilidad, ofreciendo soluciones específicas para aplicaciones de codificación y matemáticas.
Se espera que la serie Qwen2.5 desafíe a los LLMs líderes como Llama 3.1 y Mistral Large 2, demostrando que el equipo de Alibaba sigue empujando los límites en modelos de IA a gran escala. Con tamaños de parámetros que van desde 0.5 mil millones hasta 72 mil millones, esta serie cubre una amplia gama de casos de uso, desde tareas ligeras hasta aplicaciones empresariales de gran envergadura. A medida que avanza la IA, modelos como Qwen2.5 serán fundamentales para moldear el futuro de la tecnología de lenguaje generativo.
Preguntas y respuestas:
¿Cuáles son los principales avances que ofrece la serie Qwen2.5?
La serie Qwen2.5 ofrece importantes mejoras en áreas como la codificación, las matemáticas, el seguimiento de instrucciones y el soporte multilingüe. Además, su capacidad para manejar contextos largos y generar grandes cantidades de texto lo convierte en una herramienta versátil y eficiente para diversas aplicaciones.
¿Cómo se compara el modelo Qwen2.5 con otros modelos de lenguaje grande?
El modelo Qwen2.5, especialmente su versión de 72 mil millones de parámetros, puede competir con algunos de los modelos más avanzados, como Llama 3.1 y Mistral Large 2, a pesar de tener menos parámetros. Esto se debe a la optimización de su arquitectura subyacente, lo que permite un rendimiento de alto nivel con un número menor de parámetros.
¿Qué características hacen que Qwen2.5 sea adecuado para tareas de largo contexto?
El modelo Qwen2.5 soporta una longitud de contexto de hasta 128,000 tokens, lo que lo hace ideal para procesar entradas largas y complejas, como documentos legales o la generación de contenido extenso. Además, puede generar hasta 8,192 tokens, facilitando la creación de informes detallados o manuales técnicos.
¿Qué variantes especializadas incluye la serie Qwen2.5 y para qué están diseñadas?
La serie Qwen2.5 incluye dos variantes especializadas: Qwen2.5-Coder y Qwen2.5-Math. Qwen2.5-Coder está optimizado para tareas de programación y generación de código, mientras que Qwen2.5-Math está diseñado para razonamiento matemático y resolución de problemas matemáticos.
¿Qué características arquitectónicas clave tiene la serie Qwen2.5?
Entre las características arquitectónicas destacadas de Qwen2.5 se incluyen Rotary Position Embeddings (RoPE) para el procesamiento eficiente de contextos largos, la activación SwiGLU para capturar patrones complejos de manera eficiente, y RMSNorm, una técnica de normalización que mejora la estabilidad y los tiempos de convergencia durante el entrenamiento del modelo.