OpenAI lanza nuevos modelos de audio
OpenAI ha anunciado recientemente el lanzamiento de nuevos modelos de audio en su API, diseñados para mejorar la interacción entre humanos y agentes de inteligencia artificial mediante el uso de lenguaje hablado. Estos avances incluyen modelos de transcripción de voz a texto y de síntesis de texto a voz, que ofrecen una mayor precisión y personalización en diversas aplicaciones.
Nuevos modelos de transcripción de voz a texto
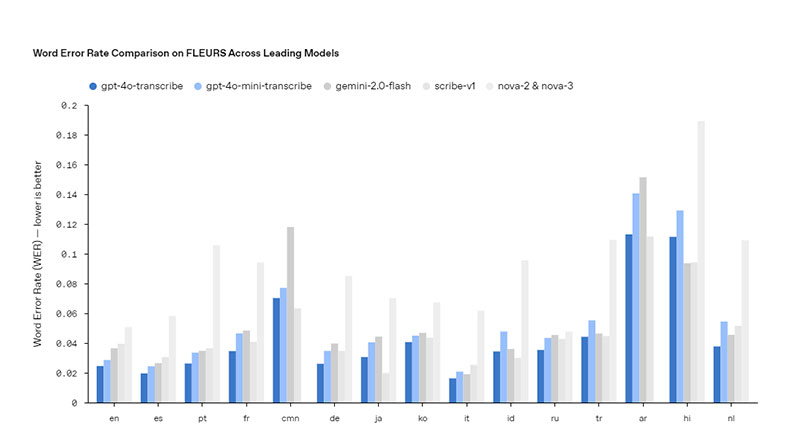
OpenAI ha introducido dos modelos principales para la transcripción de audio: gpt-4o-transcribe y gpt-4o-mini-transcribe. Estos modelos presentan mejoras significativas en la tasa de error de palabras (WER) y en el reconocimiento de múltiples idiomas, superando a los modelos anteriores como Whisper. Gracias a innovaciones en el aprendizaje por refuerzo y al entrenamiento con conjuntos de datos de audio diversos y de alta calidad, estos modelos son capaces de captar mejor los matices del habla, reducir errores de reconocimiento y aumentar la fiabilidad de las transcripciones, incluso en escenarios desafiantes con acentos marcados, entornos ruidosos o variaciones en la velocidad del habla.
Nuevo modelo de síntesis de texto a voz
Además de los modelos de transcripción, OpenAI ha lanzado el modelo gpt-4o-mini-tts, que permite convertir texto en voz con un alto grado de personalización. Por primera vez, los desarrolladores pueden instruir al modelo no solo sobre qué decir, sino también sobre cómo decirlo, permitiendo que la voz generada adopte tonalidades específicas, como la de un agente de servicio al cliente empático o la de un narrador de historias creativas. Esta capacidad desbloquea una nueva dimensión de personalización para agentes de voz, mejorando la experiencia del usuario en aplicaciones como centros de atención al cliente, narraciones y más.
Innovaciones técnicas detrás de los modelos
Los avances en estos modelos de audio se basan en varias innovaciones técnicas clave:
- Entrenamiento con datos de audio auténticos: Los modelos se han entrenado extensamente con conjuntos de datos especializados en audio, lo que ha sido crucial para optimizar su rendimiento y comprensión de los matices del habla.
- Metodologías avanzadas de destilación: Se han mejorado las técnicas de destilación, permitiendo transferir conocimientos de los modelos de audio más grandes a modelos más pequeños y eficientes, manteniendo una alta calidad conversacional y capacidad de respuesta.
- Paradigma de aprendizaje por refuerzo: En los modelos de transcripción, se ha integrado un enfoque intensivo de aprendizaje por refuerzo, elevando la precisión de la transcripción a niveles de vanguardia y reduciendo errores, lo que los hace especialmente competitivos en escenarios complejos de reconocimiento de voz.
Disponibilidad de la API
Estos nuevos modelos de audio están disponibles para todos los desarrolladores a través de la API de OpenAI. Para aquellos que ya están construyendo experiencias conversacionales con modelos basados en texto, la incorporación de los modelos de transcripción y síntesis de voz es el camino más sencillo para desarrollar un agente de voz. OpenAI también ha lanzado una integración con el Agents SDK, que simplifica este proceso de desarrollo. Para experiencias de voz a voz de baja latencia, se recomienda utilizar los modelos de speech-to-speech disponibles en la API en tiempo real.
Perspectivas futuras
Mirando hacia adelante, OpenAI planea continuar invirtiendo en mejorar la inteligencia y precisión de sus modelos de audio. Además, se explorarán formas para que los desarrolladores puedan incorporar sus propias voces personalizadas, creando experiencias aún más adaptadas a las necesidades específicas de los usuarios, siempre alineadas con los estándares de seguridad de la compañía. OpenAI también está comprometida en mantener conversaciones con legisladores, investigadores, desarrolladores y creativos sobre los desafíos y oportunidades que presentan las voces sintéticas. Estas iniciativas buscan fomentar aplicaciones innovadoras y creativas utilizando las capacidades de audio mejoradas.
Preguntas y Respuestas
¿Qué mejoras ofrecen los nuevos modelos de transcripción de OpenAI?
Los modelos gpt-4o-transcribe y gpt-4o-mini-transcribe presentan mejoras significativas en la tasa de error de palabras y en el reconocimiento de múltiples idiomas, superando a modelos anteriores como Whisper. Son capaces de captar mejor los matices del habla, reducir errores y aumentar la fiabilidad de las transcripciones, incluso en condiciones desafiantes.
¿Cómo permite el modelo gpt-4o-mini-tts personalizar la síntesis de voz?
El modelo gpt-4o-mini-tts permite a los desarrolladores instruir no solo qué decir, sino también cómo decirlo, adaptando la voz generada a tonalidades específicas, como la de un agente de servicio al cliente empático o un narrador creativo.
¿Cómo pueden los desarrolladores acceder a estos nuevos modelos de audio?
Los desarrolladores pueden acceder a los nuevos modelos de audio a través de la API de OpenAI, que incluye integraciones como el Agents SDK para facilitar el desarrollo de agentes de voz personalizados.
¿Qué planes tiene OpenAI para el futuro de sus modelos de audio?
OpenAI planea continuar mejorando la inteligencia y precisión de sus modelos de audio, explorando formas para que los desarrolladores incorporen voces personalizadas y participando en conversaciones sobre los desafíos y oportunidades de las voces sintéticas.