DINOv3: Visión Computacional Autosupervisada
El campo de la visión por computadora está presenciando una revolución gracias a DINOv3, la última innovación de Meta AI. Este modelo, que representa un salto monumental en el aprendizaje autosupervisado (SSL), se destaca por su capacidad para procesar una cantidad asombrosa de datos visuales sin necesidad de etiquetas. Entrenado con 1.700 millones de imágenes, este sistema de 7.000 millones de parámetros no solo optimiza el proceso de desarrollo, sino que también redefine el rendimiento en múltiples tareas de visión, superando incluso a soluciones especializadas. La eliminación de la dependencia de datos etiquetados es un avance crucial, especialmente en áreas donde la anotación manual es costosa, consume mucho tiempo o es simplemente inviable. Con DINOv3, se abre un camino hacia la escalabilidad masiva y una mayor generalización, lo que permite a los desarrolladores trabajar con colecciones de imágenes crudas y a gran escala de manera más eficiente.
Avance en el Aprendizaje Autosupervisado con DINOv3
La principal fortaleza de DINOv3 radica en su enfoque del aprendizaje autosupervisado, que elimina por completo la necesidad de anotaciones manuales. Esto no solo simplifica el proceso de entrenamiento, sino que también permite a los modelos escalarse a conjuntos de datos gigantescos y arquitecturas más grandes. A diferencia de los modelos tradicionales, que se adaptan a tareas específicas, el paradigma de DINOv3 le permite aprender representaciones visuales de una gran variedad de fuentes, desde imágenes naturales hasta aéreas. Este sistema va más allá de sus predecesores, demostrando que un único backbone de visión congelado puede superar a soluciones especializadas en diversas tareas visuales, como la detección de objetos, la segmentación semántica y el seguimiento de video, todo sin necesidad de un ajuste fino adicional.
Rendimiento y Aplicaciones Prácticas de DINOv3
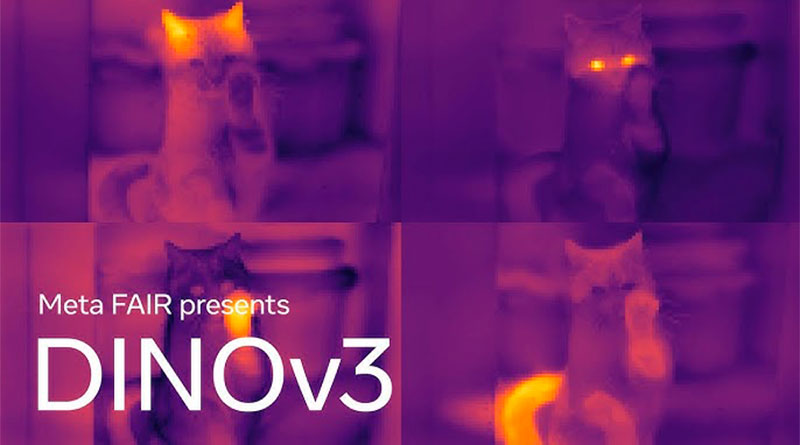
El rendimiento de DINOv3 es un claro testimonio de su potencia. El modelo genera características visuales densas y de alta calidad que mejoran significativamente el desempeño en múltiples tareas de visión. Su versatilidad lo convierte en un «codificador visual universal», capaz de aplicarse en una amplia gama de campos y dominios. Esta capacidad de usar un único backbone congelado para diversos propósitos se traduce en importantes ahorros computacionales, lo que lo hace ideal para aplicaciones en dispositivos con recursos limitados. En términos de resultados, DINOv3 ha establecido nuevos récords de rendimiento en la detección de objetos, la segmentación semántica y la estimación de profundidad monocular. Su capacidad para superar a otros modelos en la correspondencia geométrica y semántica también lo posiciona como una herramienta prometedora para futuras aplicaciones en el ámbito 3D.
Innovaciones Técnicas que Hacen a DINOv3 Único
Detrás del impresionante rendimiento de DINOv3 se encuentran varias innovaciones técnicas clave. Una de las más destacadas es el método Gram Anchoring. Esta estrategia, completamente nueva, soluciona el problema de la degradación de los mapas de características densas durante entrenamientos prolongados, asegurando que la calidad y la consistencia del modelo se mantengan a lo largo del tiempo. Además, el modelo ha sido entrenado a una escala sin precedentes, utilizando 1.700 millones de imágenes, lo que representa un aumento considerable en comparación con sus versiones anteriores. La preparación de los datos también fue meticulosa, utilizando un sistema de curación automático para garantizar una cobertura equilibrada de todos los conceptos visuales. Otro aspecto crucial es la arquitectura del modelo, una variante personalizada del Vision Transformer (ViT) con incrustaciones de posición modernas, lo que le permite evitar artefactos posicionales y mejorar su rendimiento general.
Impacto Tangible y Futuro de DINOv3
El impacto de DINOv3 va más allá de la investigación, con aplicaciones reales que ya están transformando industrias. En el sector medioambiental, organizaciones como el World Resources Institute (WRI) ya están utilizando el modelo para analizar imágenes satelitales y detectar cambios en el uso de la tierra y la pérdida de árboles con una precisión notable. Este modelo ha demostrado ser fundamental para mejorar la estimación de la altura de los árboles, reduciendo el margen de error de manera significativa. En la robótica, su eficiencia lo convierte en un candidato ideal para el desarrollo de vehículos autónomos y robots de exploración. A pesar de la transición a una licencia comercial, que ha generado debate, Meta ha puesto a disposición de la comunidad el código de entrenamiento y los modelos preentrenados, con el objetivo de fomentar la innovación y los avances en el campo de la visión por computadora. El proyecto demuestra que, si bien tiene una huella de carbono considerable, el potencial para resolver problemas globales de gran envergadura justifica la inversión en estos modelos a gran escala.
Preguntas y Respuestas
¿Qué es DINOv3 y cuál es su principal ventaja?
DINOv3 es un modelo de visión por computadora desarrollado por Meta AI que utiliza aprendizaje autosupervisado. Su principal ventaja es que no necesita datos etiquetados para entrenar, lo que permite trabajar con enormes colecciones de imágenes de forma eficiente y escalar el modelo a un tamaño sin precedentes.
¿Qué es el aprendizaje autosupervisado?
El aprendizaje autosupervisado es una técnica en inteligencia artificial donde un modelo aprende a partir de datos sin etiquetas. El sistema crea sus propias «etiquetas» o «señales» a partir de la estructura de los datos, lo que le permite descubrir patrones y características de manera autónoma, sin supervisión humana directa.
¿Cómo se diferencia DINOv3 de modelos anteriores como DINOv2?
DINOv3 supera a su predecesor, DINOv2, al ser entrenado con 12 veces más datos (1.700 millones de imágenes) y un modelo 7 veces más grande (7.000 millones de parámetros). Además, introduce innovaciones técnicas como el Gram Anchoring y un método de entrenamiento a tasa constante, lo que mejora significativamente su rendimiento y estabilidad.
¿Qué aplicaciones prácticas tiene DINOv3?
Las aplicaciones prácticas de DINOv3 son muy amplias, abarcando desde el monitoreo ambiental, como el análisis de imágenes satelitales para detectar la deforestación, hasta la robótica, los vehículos autónomos, la medicina y la manufactura. Su eficiencia y versatilidad lo hacen ideal para el despliegue en una variedad de escenarios del mundo real.
¿Por qué se considera que DINOv3 tiene un gran impacto ambiental?
El entrenamiento a gran escala de modelos de inteligencia artificial como DINOv3 requiere una cantidad masiva de energía, lo que se traduce en una huella de carbono considerable. Se estima que el proyecto completo de investigación y desarrollo consumió una cantidad de energía equivalente a 2600 toneladas de dióxido de carbono, destacando el debate sobre el coste energético de los avances tecnológicos a gran escala.