
Nueva visión inteligente activa en Gemini 3 Flash
La tecnología aplicada a la inteligencia artificial está experimentando un cambio profundo en la forma en que las máquinas entienden lo que ven. Con la llegada de la visión agéntica al modelo Gemini 3 Flash, la interacción con las imágenes deja de ser un proceso estático para convertirse en una investigación activa. Hasta ahora, la mayoría de los sistemas de inteligencia artificial analizaban una fotografía de un solo vistazo, lo que provocaba errores frecuentes al intentar identificar detalles muy pequeños o números complejos. Esta nueva capacidad permite que el modelo no solo observe, sino que interactúe con el archivo visual de forma dinámica.
De la observación pasiva al análisis dinámico
Tradicionalmente, cuando un modelo de lenguaje procesaba una imagen, lo hacía de manera pasiva. Si el sistema no lograba captar un dato específico en el primer análisis, solía rellenar los huecos mediante probabilidades, lo que generaba las conocidas alucinaciones de la inteligencia artificial. La visión agéntica rompe con este esquema al permitir que el sistema formule un plan de inspección detallado. Gracias a la ejecución de código Python, el modelo puede manipular la imagen en tiempo real para verificar información antes de dar una respuesta definitiva.
Este avance es fundamental para profesionales que requieren una precisión técnica elevada. Al reducir las conjeturas y sustituirlas por procesos verificables, el análisis de datos visuales se vuelve mucho más fiable. Ya no se trata solo de generar contenido visual, sino de lograr un entendimiento profundo que sea útil en tareas cotidianas y entornos de trabajo exigentes.
Cómo funciona el proceso de razonamiento visual
El sistema opera bajo un ciclo continuo que garantiza que cada afirmación esté respaldada por evidencia física en la imagen. Este método se divide en tres etapas principales que aseguran la calidad del resultado final:
Planificación y pensamiento crítico
En la primera fase, el modelo recibe la consulta del usuario y realiza un escaneo inicial. Aquí es donde decide qué pasos debe seguir para resolver la duda, identificando si necesita mirar más de cerca algún punto concreto.
Acción mediante herramientas técnicas
A diferencia de otros modelos, este puede ejecutar código informático para transformar la imagen. Puede realizar recortes, rotar el archivo o incluso hacer anotaciones sobre los píxeles para organizar la información detectada.
Observación y respuesta final
Una vez realizada la manipulación, el modelo analiza el nuevo material generado. Con estos datos adicionales en su memoria de trabajo, emite una conclusión basada en hechos visuales comprobados, minimizando drásticamente el margen de error.
Funciones avanzadas para el uso diario
La integración de estas herramientas permite realizar tareas que antes eran imposibles o muy imprecisas para una inteligencia artificial convencional. Entre las capacidades más destacadas encontramos:
- Zoom inteligente: El sistema detecta automáticamente si hay detalles minúsculos que requieren una ampliación. Al generar un recorte de alta resolución, puede leer etiquetas pequeñas o códigos de barras con exactitud.
- Marcado visual: El modelo puede dibujar sobre la imagen para explicar su razonamiento. Si se le pide contar elementos, los señalará individualmente con cuadros y números, demostrando que comprende la ubicación de cada objeto.
- Gráficos y matemáticas: Puede extraer datos de tablas complejas y transformarlos en gráficos profesionales de forma inmediata, asegurando que los cálculos matemáticos sean exactos.
Mejora en el rendimiento y disponibilidad
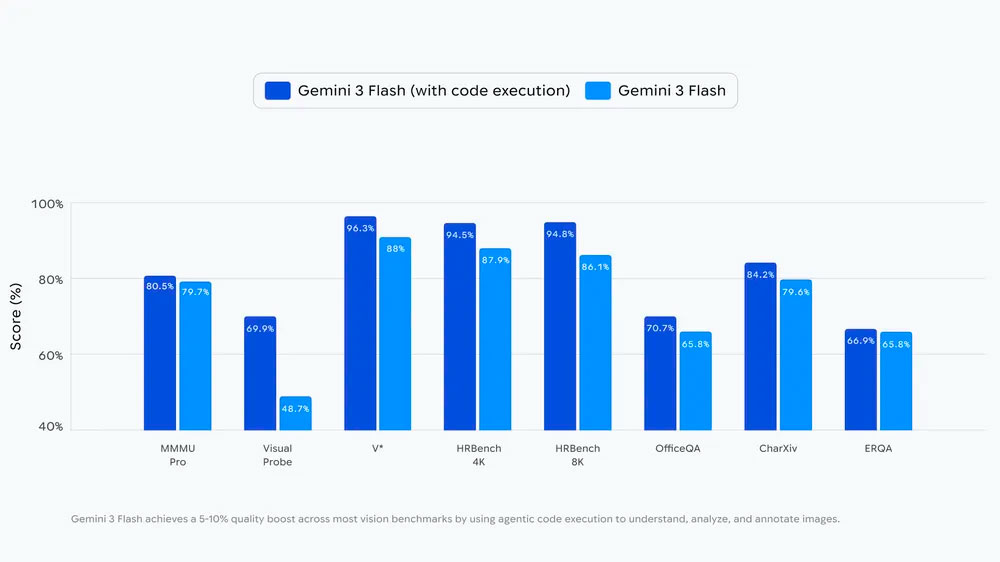
Las pruebas técnicas indican que esta capacidad de actuar sobre el contenido visual mejora la precisión entre un 5% y un 10% en comparación con modelos que solo observan. Este crecimiento es especialmente notable en tareas de comprensión de documentos y resolución de problemas lógicos visuales. Actualmente, esta tecnología está disponible para especialistas a través de plataformas de desarrollo y se está incorporando poco a poco en la aplicación oficial para el público general bajo el modo de pensamiento avanzado.
El futuro de esta herramienta apunta a una autonomía total, donde el sistema pueda realizar búsquedas externas para contrastar lo que ve o utilizar herramientas de localización para dar un contexto geográfico mucho más amplio a sus respuestas.
Preguntas y respuestas
¿Qué es la visión agéntica en la inteligencia artificial?
Es una capacidad que permite a los modelos de inteligencia artificial interactuar con las imágenes, realizando acciones como ampliar detalles o ejecutar código para analizarlas mejor en lugar de solo mirarlas de forma estática.
¿Cómo ayuda Python a la comprensión de imágenes?
El modelo utiliza Python para realizar tareas matemáticas exactas y manipulaciones técnicas sobre la imagen, lo que evita que la IA tenga que adivinar detalles y garantiza resultados basados en datos reales.
¿Dónde se puede probar esta nueva función?
Está disponible para desarrolladores en Google AI Studio y se está integrando progresivamente para los usuarios de la aplicación móvil dentro de las opciones de modelos de pensamiento.







