DeepSeek-R1: razonador open source
DeepSeek, la startup china de inteligencia artificial, ha lanzado DeepSeek-R1, un modelo de razonamiento avanzado que compite con gigantes como OpenAI o1. Basado en el innovador DeepSeek V3, no solo iguala en rendimiento en matemáticas, programación y razonamiento lógico, sino que lo hace a un costo drásticamente menor, con ahorros del 90-95% frente a sus rivales comerciales.
Características destacadas de DeepSeek-R1
DeepSeek-R1 utiliza una combinación de aprendizaje por refuerzo (RL) y entrenamiento supervisado para resolver problemas complejos mediante cadenas de razonamiento avanzadas. En pruebas de referencia obtuvo:
- 79.8% en AIME 2024 (razonamiento matemático avanzado).
- 97.3% en MATH-500 (resolución de problemas matemáticos).
- Un puntaje de 2,029 en Codeforces, superando al 96.3% de los programadores humanos.
Estos logros lo posicionan como un modelo competitivo, incluso frente a modelos más grandes como GPT-4o y Claude 3.5.
Modelos destilados de DeepSeek-R1
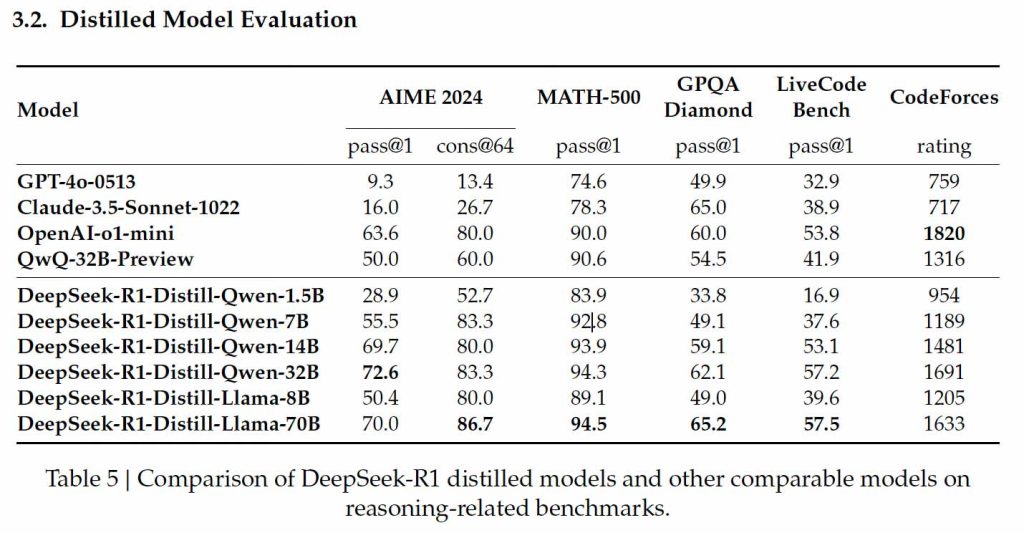
La destilación permite crear versiones más pequeñas y eficientes de modelos grandes, manteniendo capacidades clave de razonamiento mientras se reducen los requisitos computacionales. DeepSeek aplicó esta técnica a sus arquitecturas Qwen y Llama, generando modelos compactos ideales para su instalación en hardware doméstico.
Modelos destilados basados en Qwen
- Deepseek-R1-Qwen-1.5B: Compacto, con un 83.9% en MATH-500, ideal para matemáticas básicas. Sin embargo, su desempeño es limitado en programación (16.9% en LiveCodeBench).
- Deepseek-R1-Qwen-7B: Logra un 92.8% en MATH-500 y un 49.1% en GPQA Diamond, pero sigue siendo moderado en tareas de codificación (37.6% en LiveCodeBench).
- Deepseek-R1-Qwen-14B: Destacado en MATH-500 (93.9%) y GPQA Diamond (59.1%), con un mejor desempeño en programación (53.1% en LiveCodeBench y 1481 en Codeforces).
- Deepseek-R1-Qwen-32B: El modelo más avanzado basado en Qwen, con un 94.3% en MATH-500 y 62.1% en GPQA Diamond, junto con un rendimiento versátil en programación (57.2% en LiveCodeBench y 1691 en Codeforces).
Modelos destilados basados en Llama
- Deepseek-R1-Llama-8B: Compacto y accesible, obtiene un 89.1% en MATH-500 y un rendimiento razonable en GPQA Diamond (49.0%). En codificación, sus capacidades son limitadas (39.6% en LiveCodeBench).
- Deepseek-R1-Llama-70B: El más grande y potente, con un 94.5% en MATH-500 y un 86.7% en AIME 2024. Su rendimiento en LiveCodeBench (57.5%) y Codeforces (1633) lo posiciona como una alternativa eficiente incluso frente al o1-mini de OpenAI.
Accesibilidad y costo
DeepSeek-R1 y sus modelos destilados están disponibles en Hugging Face con una licencia MIT, listos para instalación local. Esto democratiza el acceso a tecnología avanzada, permitiendo que desarrolladores con hardware doméstico utilicen modelos como Llama-8B y Qwen-7B. Además, los costos son significativamente menores:
- $0.55 por millón de tokens de entrada.
- $2.19 por millón de tokens de salida, frente a los $15 y $60 de OpenAI o1.
Preguntas frecuentes
¿Qué es DeepSeek-R1?
Es un modelo de razonamiento open source que iguala el rendimiento de OpenAI o1, pero con un costo significativamente menor.
¿Qué son los modelos destilados de DeepSeek?
Son versiones compactas y eficientes de DeepSeek-R1, diseñadas para ejecutarse en hardware doméstico sin comprometer capacidades esenciales.
¿Dónde están disponibles los modelos de DeepSeek?
Se encuentran en Hugging Face con licencia MIT para descarga y uso en proyectos personales o comerciales.
¿Cuáles son las ventajas de los modelos basados en Qwen y Llama?
Los modelos Qwen priorizan la escalabilidad, mientras que los basados en Llama destacan en tareas avanzadas de razonamiento matemático y factual.