Gemma 4 12B: modelo multimodal sin codificador
Gemma 4 12B: modelo multimodal eficiente para laptops
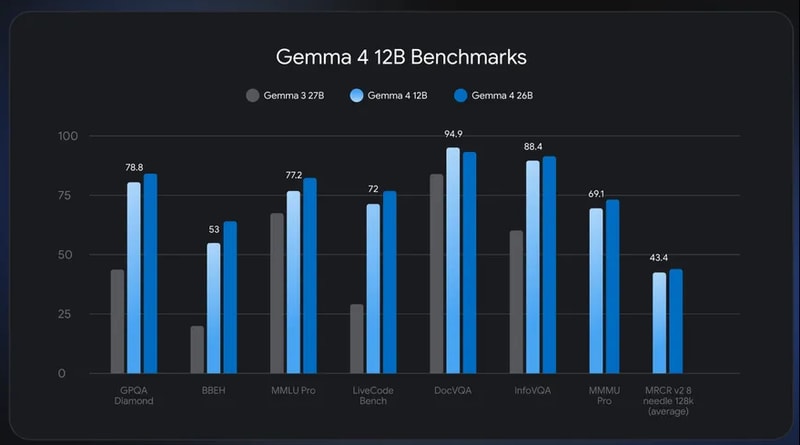
Gemma 4 12B es el último avance en modelos multimodales que se adapta a las laptops sin requerir un codificador para entradas de audio y visión. Diseñado para ofrecer una inteligencia de alto rendimiento, este modelo combina eficiencia móvil con capacidades de razonamiento avanzadas. Gracias a su arquitectura unificada, Gemma 4 12B ingresa directamente las entradas visuales y auditivas en el núcleo del modelo de lenguaje sin necesidad de codificadores separados. Con esto, reduce su huella de memoria y mejora la rapidez de procesamiento.
Innovaciones de Gemma 4 12B
Este modelo multimodal ha sido optimizado para funcionar con solo 16GB de VRAM o memoria unificada, permitiendo experiencias avanzadas en hardware común sin comprometer la velocidad. Gemma 4 12B viene equipado con características que maximizan su potencial en entornos de desarrollo:
- Arquitectura unificada novedosa: integración directa de entradas de visión y audio en el modelo central.
- Razonamiento avanzado: rendimiento cercano a modelos más grandes con razonamientos y flujos de trabajo complejos.
- Preparado para laptops: ejecutarse localmente sin sacrificar sus capacidades.
- Accesibilidad y apertura: disponible bajo una licencia Apache 2.0 que facilita su integración en múltiples ecosistemas de desarrollo.
- Compatible con Multi-Token Prediction: esta función ayuda a reducir la latencia en los procesos.
Procesamiento de entradas multimodales
La clave del éxito de Gemma 4 12B es su enfoque eficiente en el manejo de datos visuales y auditivos. A diferencia de modelos antiguos que requerían codificadores para traducir imágenes y audio, Gemma 4 utiliza módulos de incrustación ligeros. En el caso del video, se realiza un único paso de multiplicación de matrices, logrando que el modelo pueda procesar estos datos de manera directa. Para el audio, el modelo omite completamente el codificador, proyectando las señales de audio en el mismo espacio dimensional que los tokens de texto.
Inicia tu experiencia con Gemma 4 12B
Los desarrolladores tienen múltiples formas de comenzar a emplear Gemma 4 12B:
- Experimenta por ti mismo: Prueba en plataformas como LM Studio y Google AI Edge Gallery App.
- Descarga los pesos preentrenados: Disponibles en Hugging Face y Kaggle para un acceso rápido.
- Documentación y recursos: Consulta la documentación oficial para desarrolladores y comienza con un cuaderno de inicio rápido.
- Desarrollo ágil: Usa herramientas como Hugging Face Transformers y vLLM para implementar tuberías de inferencia locales o pule tu proyecto con Unsloth.
- Despliegue personalizado: Implanta tu aplicación a través de plataformas como Google Cloud o Cloud Run.
Preguntas frecuentes
¿Qué hace especial a Gemma 4 12B?
Su arquitectura unificada sin codificadores que permite procesar entradas visuales y auditivas directamente en el núcleo del modelo de lenguaje.
¿Qué requisitos de hardware tiene?
Puedes ejecutarlo en laptops con 16GB de VRAM o memoria unificada, lo que facilita su uso en equipos de uso cotidiano.
¿Dónde puedo integrar Gemma 4 12B?
Está disponible para descarga e integración en plataformas como Hugging Face y Kaggle, y puedes usarlo con herramientas de desarrollo locales o desplegar en la nube.