GLM-4.6: el modelo que desafía a la IA propietaria
La carrera por la inteligencia artificial más avanzada no se detiene, y el lanzamiento del modelo GLM-4.6 por parte de la empresa china Z.ai (antes conocida como Zhipu AI) ha marcado un antes y un después. Este modelo de lenguaje general de código abierto se presenta como un competidor directo y muy serio para sistemas propietarios de grandes nombres como Anthropic y OpenAI. El GLM-4.6 no solo mejora significativamente a su predecesor, sino que se posiciona como una de las herramientas más potentes para tareas complejas, especialmente en el ámbito de la programación y el razonamiento.
El ascenso de la inteligencia artificial de código abierto
El panorama de la IA a finales de 2025 está dominado por una competencia feroz, sobre todo en el desarrollo de modelos especializados, conocidos como «coding agents». Estos son vistos por muchos expertos como un paso crucial hacia la Inteligencia Artificial General (AGI). Mientras que compañías estadounidenses como OpenAI (con la serie GPT) y Anthropic (con Claude) han liderado la narrativa, Z.ai está cambiando las reglas del juego. El lanzamiento de GLM-4.6 en septiembre de 2025 es una estrategia clara para retar el dominio occidental en este sector. Este modelo representa una tendencia creciente: la IA de código abierto está evolucionando de ser una simple alternativa a una opción verdaderamente competitiva frente a los sistemas cerrados y de pago.
Análisis técnico: el poder detrás de GLM-4.6
El éxito de GLM-4.6 se debe en gran parte a su avanzada arquitectura. El modelo utiliza una arquitectura Transformer de Mezcla de Expertos (MoE), lo que le permite manejar una escala enorme (355 mil millones de parámetros totales) manteniendo una eficiencia computacional notable. De todos esos parámetros, solo 32 mil millones están activos en cada proceso de inferencia. Este diseño es clave para su alto rendimiento y eficiencia.
Características destacadas y mejoras clave
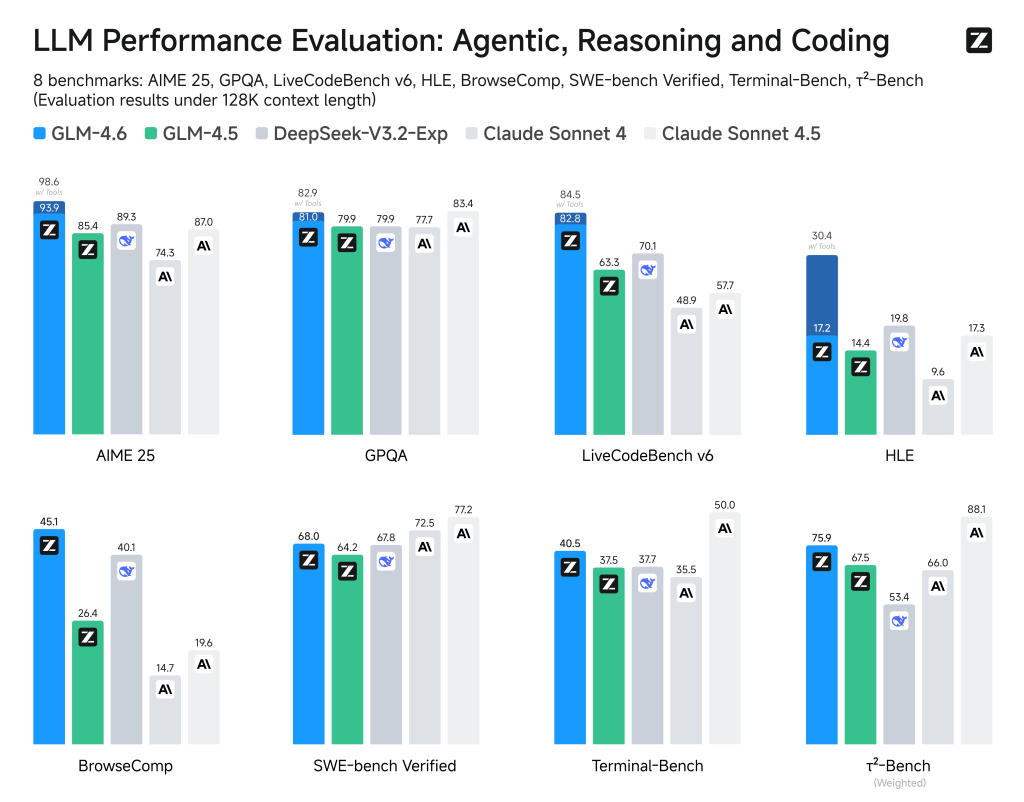
Una de las mejoras más impresionantes es la expansión de su ventana de contexto, que ha pasado de 128.000 a 200.000 tokens. Esto permite al modelo procesar documentos o bases de código mucho más grandes en una sola interacción, facilitando la ejecución de tareas de agente complejas. Además, su rendimiento en codificación ha mejorado notablemente. En pruebas prácticas, el GLM-4.6 ha demostrado estar casi a la par con el prestigioso Claude Sonnet 4, lo que es un logro significativo para un modelo de pesos abiertos. Otro punto fuerte es la eficiencia de tokens, ya que en tareas de razonamiento ha reducido el consumo en un 14%, lo que se traduce en costos operativos mucho menores.
El rendimiento en benchmarks y la paridad práctica
Los resultados en métricas de evaluación demuestran su poder. Por ejemplo, en el índice Artificial Analysis Intelligence Index v3.0, GLM-4.6 obtuvo 56 puntos en modo razonamiento, superando con creces a su versión anterior. Pero donde realmente brilla es en las pruebas prácticas. En la evaluación CC-Bench, que utiliza evaluadores humanos para tareas de desarrollo reales, el modelo logró una tasa de victoria de casi el 49% contra Claude Sonnet 4. Este resultado se considera un empate técnico, confirmando su paridad en escenarios de desarrollo cotidianos. Esto lo consolida no solo como el modelo líder desarrollado en China, sino como el modelo de código abierto más potente del mundo para la programación a finales de 2025.
Usos prácticos y el ecosistema de acceso
Las capacidades mejoradas del GLM-4.6 lo hacen ideal para multitud de aplicaciones. En codificación con IA, es excelente para lenguajes como Python, JavaScript y Java, mostrando una habilidad particular para generar código frontend visualmente pulido. También es un aliado poderoso en la oficina inteligente, mejorando la calidad en la creación de presentaciones de PowerPoint y la automatización de documentos con diseños estéticos y lógicos.
Z.ai ha adoptado una estrategia de apertura para impulsar su adopción. El modelo es accesible tanto a través de su API oficial (con planes muy económicos) como de proveedores externos como OpenRouter y Novita. Lo más importante es que los pesos del modelo están disponibles bajo licencias de código abierto (MIT/Apache 2.0) en plataformas como Hugging Face. Esta apertura democratiza el acceso a tecnología de vanguardia, permitiendo que desarrolladores, startups e investigadores puedan implementarlo y personalizarlo sin los altos costos de los sistemas propietarios. De hecho, los costos de inferencia son drásticamente más bajos que los de sus principales competidores.
Preguntas y respuestas sobre GLM-4.6
¿Qué es la arquitectura de Mezcla de Expertos (MoE)?
La arquitectura MoE es un tipo de red neuronal que divide el modelo en varios submódulos o «expertos». Durante el procesamiento, solo un pequeño subconjunto de estos expertos se activa para una entrada específica. Esto permite que el modelo sea masivo en tamaño (cientos de miles de millones de parámetros) pero muy eficiente en el uso de recursos y rápido en la inferencia, ya que no se necesita calcular todo el modelo completo en cada tarea.
¿Qué significa una ventana de contexto de 200.000 tokens?
La ventana de contexto se refiere a la cantidad de información (palabras, fragmentos de código, etc.) que el modelo puede «recordar» y procesar activamente en una sola interacción. Una ventana de 200.000 tokens significa que el GLM-4.6 puede analizar y generar código o texto basándose en una cantidad enorme de datos a la vez, lo que es crucial para tareas de programación complejas o el análisis de documentos muy extensos.
¿Es posible usar GLM-4.6 de forma gratuita?
Sí, aunque el acceso a través de las APIs oficiales o externas tiene un costo muy bajo, el hecho de que el modelo esté bajo licencia de código abierto y sus pesos estén disponibles permite a cualquiera con la infraestructura necesaria autoalojarlo. Sin embargo, los requisitos de hardware para ejecutar un modelo tan grande son de nivel empresarial (múltiples GPUs de alta gama), haciendo que el acceso por API sea la opción más viable para la mayoría de los usuarios y desarrolladores individuales.